 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Computational Fluid Dynamics on HPC Systems
May 13, 2022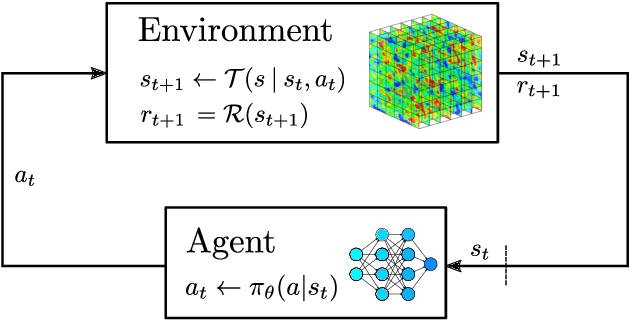

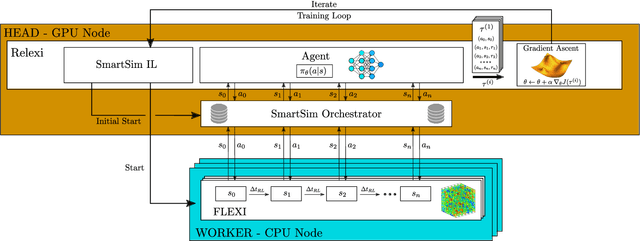
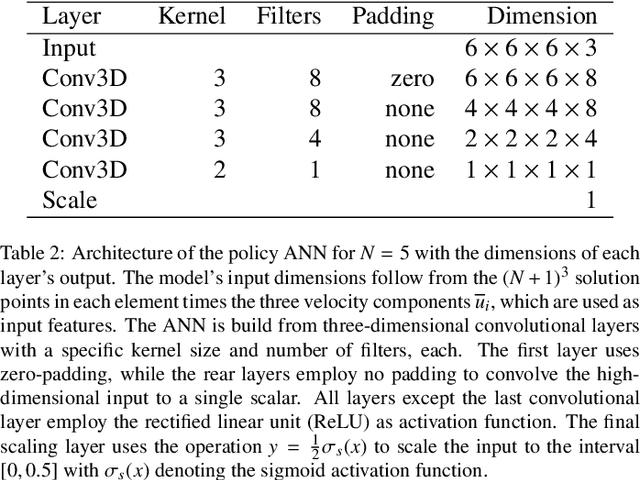
Reinforcement learning (RL) is highly suitable for devising control strategies in the context of dynamical systems. A prominent instance of such a dynamical system is the system of equations governing fluid dynamics. Recent research results indicate that RL-augmented computational fluid dynamics (CFD) solvers can exceed the current state of the art, for example in the field of turbulence modeling. However, while in supervised learning, the training data can be generated a priori in an offline manner, RL requires constant run-time interaction and data exchange with the CFD solver during training. In order to leverage the potential of RL-enhanced CFD, the interaction between the CFD solver and the RL algorithm thus have to be implemented efficiently on high-performance computing (HPC) hardware. To this end, we present Relexi as a scalable RL framework that bridges the gap between machine learning workflows and modern CFD solvers on HPC systems providing both components with its specialized hardware. Relexi is built with modularity in mind and allows easy integration of various HPC solvers by means of the in-memory data transfer provided by the SmartSim library. Here, we demonstrate that the Relexi framework can scale up to hundreds of parallel environment on thousands of cores. This allows to leverage modern HPC resources to either enable larger problems or faster turnaround times. Finally, we demonstrate the potential of an RL-augmented CFD solver by finding a control strategy for optimal eddy viscosity selection in large eddy simulations.