 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconfounding and Causal Regularization for Stability and External Validity
Aug 14, 2020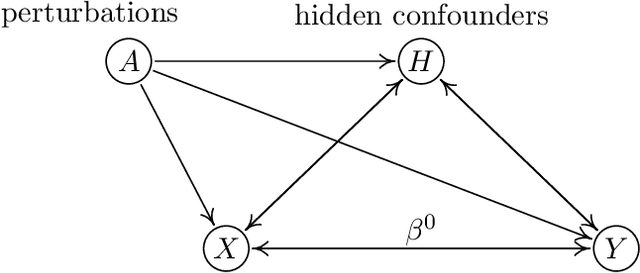
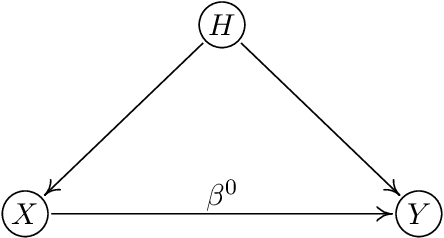
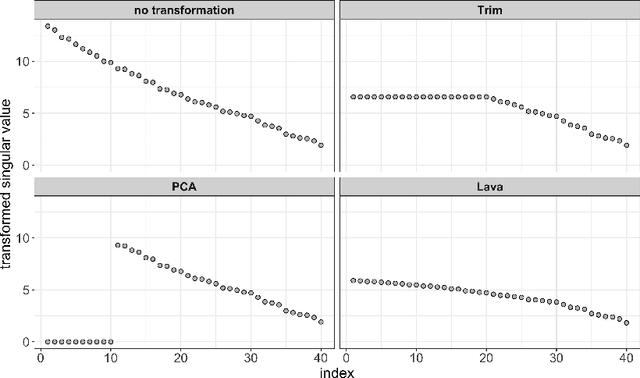
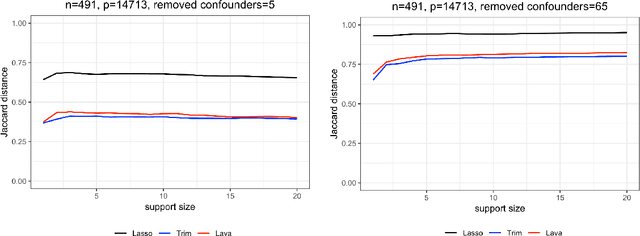
We review some recent work on removing hidden confounding and causal regularization from a unified viewpoint. We describe how simple and user-friendly techniques improve stability, replicability and distributional robustness in heterogeneous data. In this sense, we provide additional thoughts to the issue on concept drift, raised by Efron (2020), when the data generating distribution is changing.
Distributional Random Forests: Heterogeneity Adjustment and Multivariate Distributional Regression
May 29, 2020
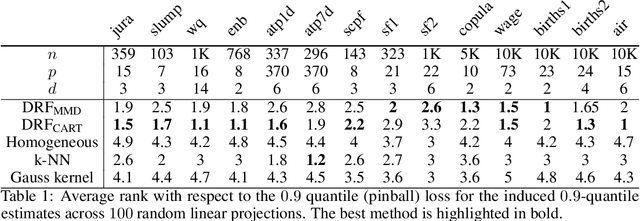
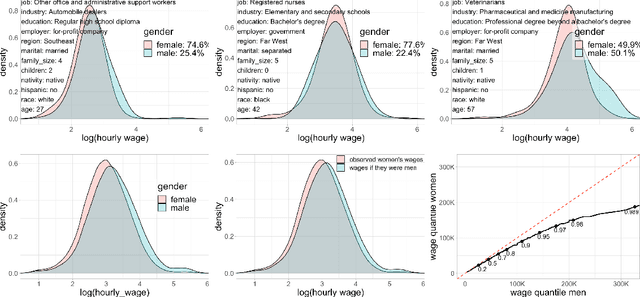

We propose an adaptation of the Random Forest algorithm to estimate the conditional distribution of a possibly multivariate response. We suggest a new splitting criterion based on the MMD two-sample test, which is suitable for detecting heterogeneity in multivariate distributions. The weights provided by the forest can be conveniently used as an input to other methods in order to locally solve various learning problems. The code is available as \texttt{R}-package \texttt{drf}.