 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Algorithms for Keyphrase Generation: Instruction-Based LLMs for Russian Scientific Keyphrases
Oct 23, 2024Keyphrase selection is a challenging task in natural language processing that has a wide range of applications. Adapting existing supervised and unsupervised solutions for the Russian language faces several limitations due to the rich morphology of Russian and the limited number of training datasets available. Recent studies conducted on English texts show that large language models (LLMs) successfully address the task of generating keyphrases. LLMs allow achieving impressive results without task-specific fine-tuning, using text prompts instead. In this work, we access the performance of prompt-based methods for generating keyphrases for Russian scientific abstracts. First, we compare the performance of zero-shot and few-shot prompt-based methods, fine-tuned models, and unsupervised methods. Then we assess strategies for selecting keyphrase examples in a few-shot setting. We present the outcomes of human evaluation of the generated keyphrases and analyze the strengths and weaknesses of the models through expert assessment. Our results suggest that prompt-based methods can outperform common baselines even using simple text prompts.
Exploring Fine-tuned Generative Models for Keyphrase Selection: A Case Study for Russian
Sep 18, 2024Keyphrase selection plays a pivotal role within the domain of scholarly texts, facilitating efficient information retrieval, summarization, and indexing. In this work, we explored how to apply fine-tuned generative transformer-based models to the specific task of keyphrase selection within Russian scientific texts. We experimented with four distinct generative models, such as ruT5, ruGPT, mT5, and mBART, and evaluated their performance in both in-domain and cross-domain settings. The experiments were conducted on the texts of Russian scientific abstracts from four domains: mathematics & computer science, history, medicine, and linguistics. The use of generative models, namely mBART, led to gains in in-domain performance (up to 4.9% in BERTScore, 9.0% in ROUGE-1, and 12.2% in F1-score) over three keyphrase extraction baselines for the Russian language. Although the results for cross-domain usage were significantly lower, they still demonstrated the capability to surpass baseline performances in several cases, underscoring the promising potential for further exploration and refinement in this research field.
Cross-Domain Robustness of Transformer-based Keyphrase Generation
Dec 17, 2023Modern models for text generation show state-of-the-art results in many natural language processing tasks. In this work, we explore the effectiveness of abstractive text summarization models for keyphrase selection. A list of keyphrases is an important element of a text in databases and repositories of electronic documents. In our experiments, abstractive text summarization models fine-tuned for keyphrase generation show quite high results for a target text corpus. However, in most cases, the zero-shot performance on other corpora and domains is significantly lower. We investigate cross-domain limitations of abstractive text summarization models for keyphrase generation. We present an evaluation of the fine-tuned BART models for the keyphrase selection task across six benchmark corpora for keyphrase extraction including scientific texts from two domains and news texts. We explore the role of transfer learning between different domains to improve the BART model performance on small text corpora. Our experiments show that preliminary fine-tuning on out-of-domain corpora can be effective under conditions of a limited number of samples.
Applying Transformer-based Text Summarization for Keyphrase Generation
Sep 08, 2022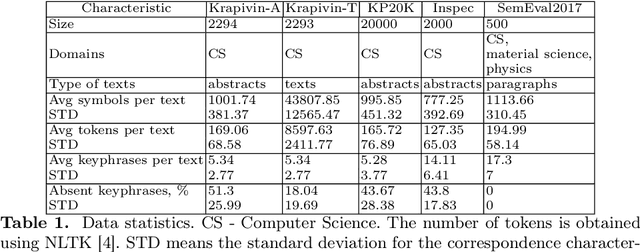

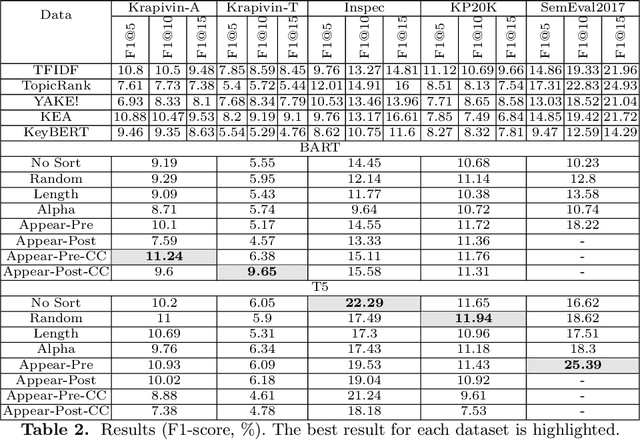
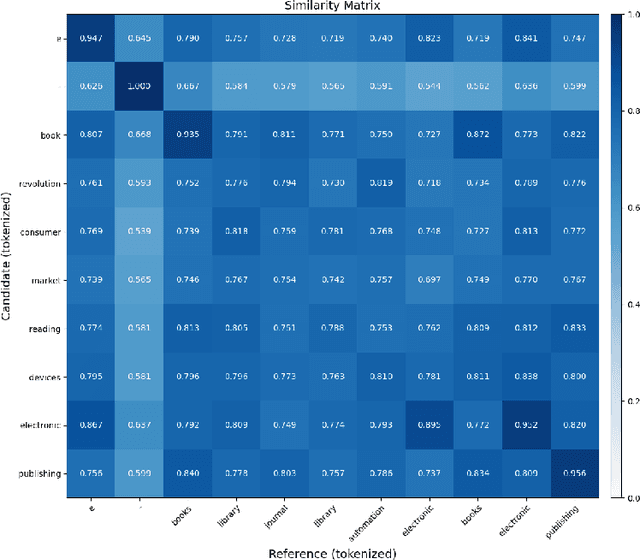
Keyphrases are crucial for searching and systematizing scholarly documents. Most current methods for keyphrase extraction are aimed at the extraction of the most significant words in the text. But in practice, the list of keyphrases often includes words that do not appear in the text explicitly. In this case, the list of keyphrases represents an abstractive summary of the source text. In this paper, we experiment with popular transformer-based models for abstractive text summarization using four benchmark datasets for keyphrase extraction. We compare the results obtained with the results of common unsupervised and supervised methods for keyphrase extraction. Our evaluation shows that summarization models are quite effective in generating keyphrases in the terms of the full-match F1-score and BERTScore. However, they produce a lot of words that are absent in the author's list of keyphrases, which makes summarization models ineffective in terms of ROUGE-1. We also investigate several ordering strategies to concatenate target keyphrases. The results showed that the choice of strategy affects the performance of keyphrase generation.
MIPT-NSU-UTMN at SemEval-2021 Task 5: Ensembling Learning with Pre-trained Language Models for Toxic Spans Detection
Apr 10, 2021
This paper describes our system for SemEval-2021 Task 5 on Toxic Spans Detection. We developed ensemble models using BERT-based neural architectures and post-processing to combine tokens into spans. We evaluated several pre-trained language models using various ensemble techniques for toxic span identification and achieved sizable improvements over our baseline fine-tuned BERT models. Finally, our system obtained a F1-score of 67.55% on test data.