 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Transformer-based Text Summarization for Keyphrase Generation
Paper and Code
Sep 08, 2022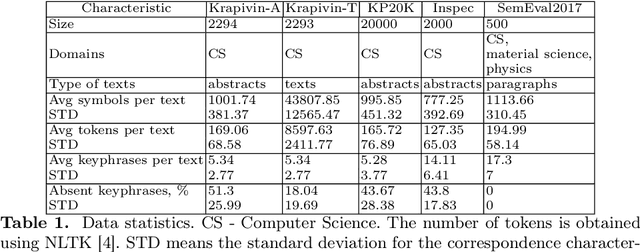

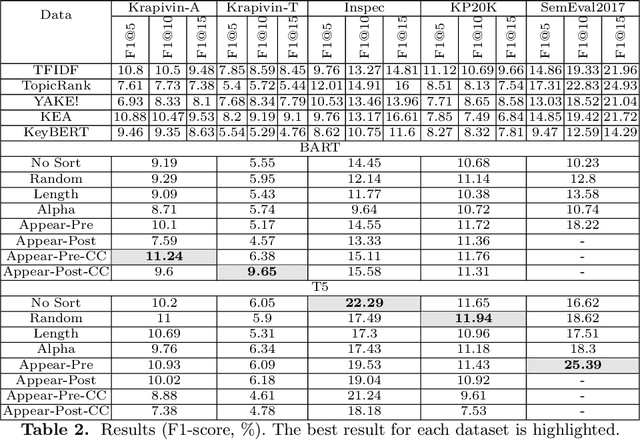
Keyphrases are crucial for searching and systematizing scholarly documents. Most current methods for keyphrase extraction are aimed at the extraction of the most significant words in the text. But in practice, the list of keyphrases often includes words that do not appear in the text explicitly. In this case, the list of keyphrases represents an abstractive summary of the source text. In this paper, we experiment with popular transformer-based models for abstractive text summarization using four benchmark datasets for keyphrase extraction. We compare the results obtained with the results of common unsupervised and supervised methods for keyphrase extraction. Our evaluation shows that summarization models are quite effective in generating keyphrases in the terms of the full-match F1-score and BERTScore. However, they produce a lot of words that are absent in the author's list of keyphrases, which makes summarization models ineffective in terms of ROUGE-1. We also investigate several ordering strategies to concatenate target keyphrases. The results showed that the choice of strategy affects the performance of keyphrase generation.