 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization Control in Diffusion Models from Denoising-centric Perspective
Jan 29, 2026Controlling memorization in diffusion models is critical for applications that require generated data to closely match the training distribution. Existing approaches mainly focus on data centric or model centric modifications, treating the diffusion model as an isolated predictor. In this paper, we study memorization in diffusion models from a denoising centric perspective. We show that uniform timestep sampling leads to unequal learning contributions across denoising steps due to differences in signal to noise ratio, which biases training toward memorization. To address this, we propose a timestep sampling strategy that explicitly controls where learning occurs along the denoising trajectory. By adjusting the width of the confidence interval, our method provides direct control over the memorization generalization trade off. Experiments on image and 1D signal generation tasks demonstrate that shifting learning emphasis toward later denoising steps consistently reduces memorization and improves distributional alignment with training data, validating the generality and effectiveness of our approach.
Object-RPE: Dense 3D Reconstruction and Pose Estimation with Convolutional Neural Networks for Warehouse Robots
Sep 30, 2019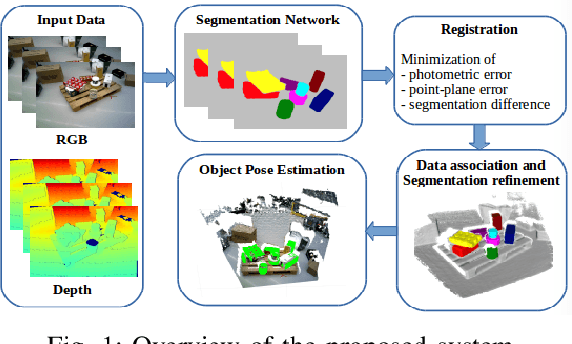
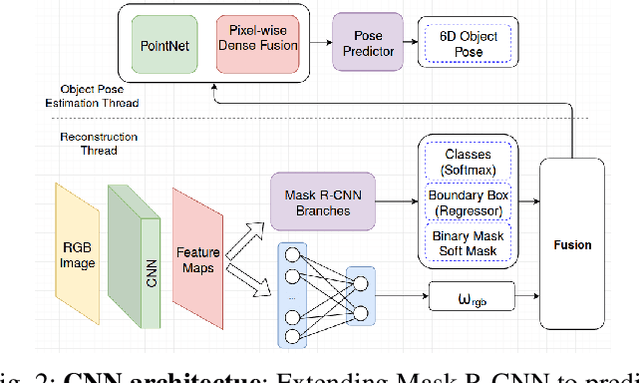


We present an approach for recognizing all objects in a scene and estimating their full pose from an accurate 3D instance-aware semantic reconstruction using an RGB-D camera. Our framework couples convolutional neural networks (CNNs) and a state-of-the-art dense Simultaneous Localisation and Mapping (SLAM) system, ElasticFusion, to achieve both high-quality semantic reconstruction as well as robust 6D pose estimation for relevant objects. While the main trend in CNN-based 6D pose estimation has been to infer object's position and orientation from single views of the scene, our approach explores performing pose estimation from multiple viewpoints, under the conjecture that combining multiple predictions can improve the robustness of an object detection system. The resulting system is capable of producing high-quality object-aware semantic reconstructions of room-sized environments, as well as accurately detecting objects and their 6D poses. The developed method has been verified through experimental validation on the YCB-Video dataset and a newly collected warehouse object dataset. Experimental results confirmed that the proposed system achieves improvements over state-of-the-art methods in terms of surface reconstruction and object pose prediction. Our code and video are available at https://sites.google.com/view/object-rpe.
High-quality Instance-aware Semantic 3D Map Using RGB-D Camera
Mar 26, 2019



We present a mapping system capable of constructing detailed instance-level semantic models of room-sized indoor environments by means of an RGB-D camera. In this work, we integrate deep-learning based instance segmentation and classification into a state of the art RGB-D SLAM system. We leverage the pipeline of ElasticFusion \cite{whelan2016elasticfusion} as a backbone, and propose modifications of the registration cost function to make full use of the instance class labels in the process. The proposed objective function features tunable weights for the depth, appearance, and semantic information channels, which can be learned from data. The resulting system is capable of producing accurate semantic maps of room-sized environments, as well as reconstructing highly detailed object-level models. The developed method has been verified through experimental validation on the TUM RGB-D SLAM benchmark and the YCB video dataset. Our results confirmed that the proposed system performs favorably in terms of trajectory estimation, surface reconstruction, and segmentation quality in comparison to other state-of-the-art systems.