Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal and efficient text counterfactuals using Graph Neural Networks
Aug 04, 2024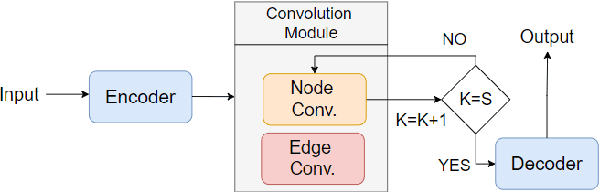
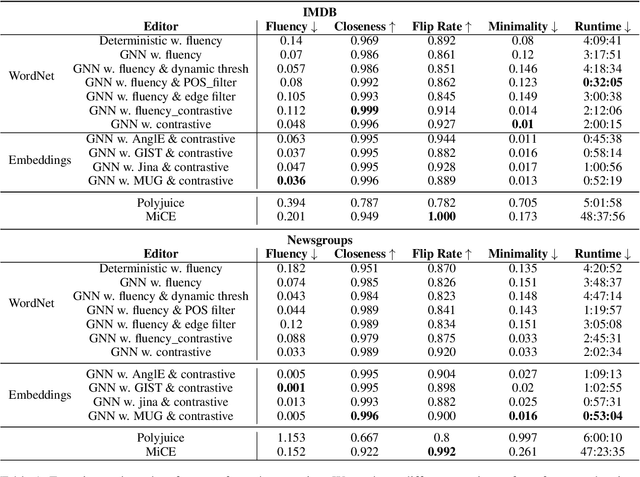
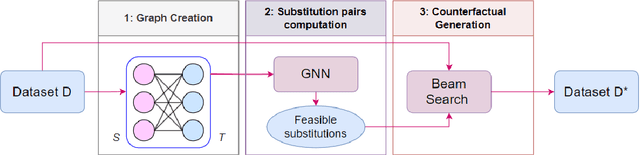
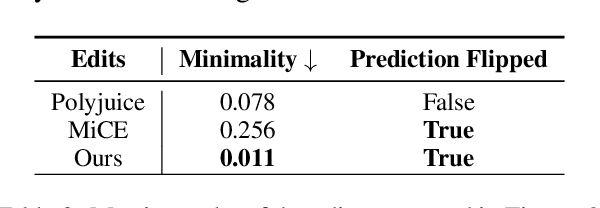
As NLP models become increasingly integral to decision-making processes, the need for explainability and interpretability has become paramount. In this work, we propose a framework that achieves the aforementioned by generating semantically edited inputs, known as counterfactual interventions, which change the model prediction, thus providing a form of counterfactual explanations for the model. We test our framework on two NLP tasks - binary sentiment classification and topic classification - and show that the generated edits are contrastive, fluent and minimal, while the whole process remains significantly faster that other state-of-the-art counterfactual editors.
Via