 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEC-CNN: A Consecutive Expansion-Contraction Convolutional Network for Very Small Resolution Medical Image Classification
Sep 27, 2022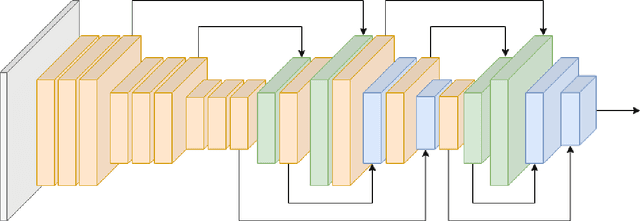
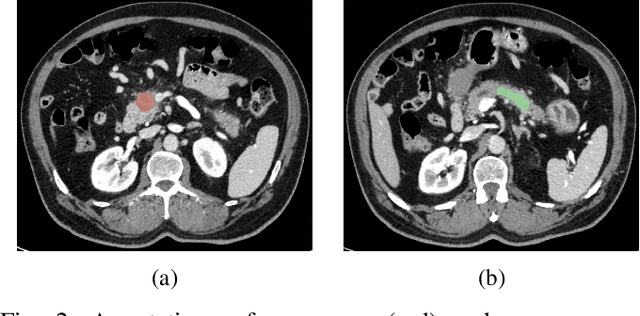
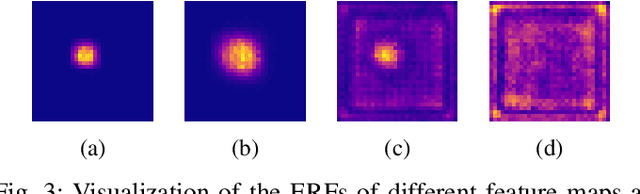
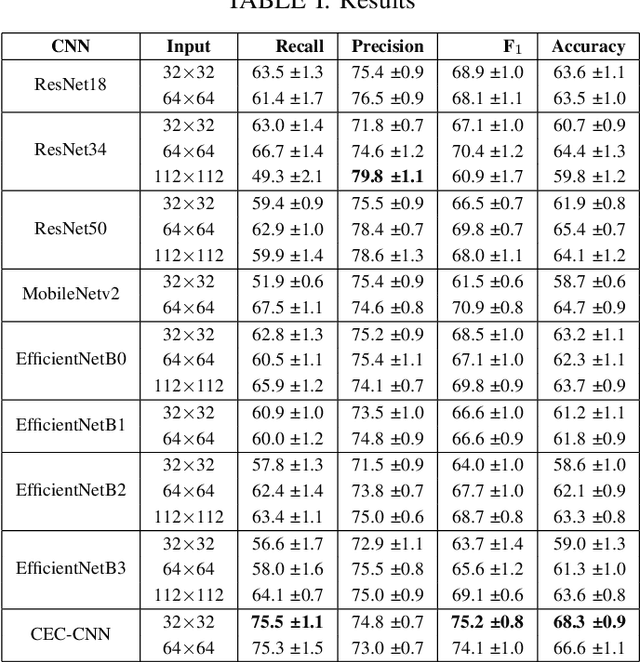
Deep Convolutional Neural Networks (CNNs) for image classification successively alternate convolutions and downsampling operations, such as pooling layers or strided convolutions, resulting in lower resolution features the deeper the network gets. These downsampling operations save computational resources and provide some translational invariance as well as a bigger receptive field at the next layers. However, an inherent side-effect of this is that high-level features, produced at the deep end of the network, are always captured in low resolution feature maps. The inverse is also true, as shallow layers always contain small scale features. In biomedical image analysis engineers are often tasked with classifying very small image patches which carry only a limited amount of information. By their nature, these patches may not even contain objects, with the classification depending instead on the detection of subtle underlying patterns with an unknown scale in the image's texture. In these cases every bit of information is valuable; thus, it is important to extract the maximum number of informative features possible. Driven by these considerations, we introduce a new CNN architecture which preserves multi-scale features from deep, intermediate, and shallow layers by utilizing skip connections along with consecutive contractions and expansions of the feature maps. Using a dataset of very low resolution patches from Pancreatic Ductal Adenocarcinoma (PDAC) CT scans we demonstrate that our network can outperform current state of the art models.
Sparsely Activated Networks
Jul 12, 2019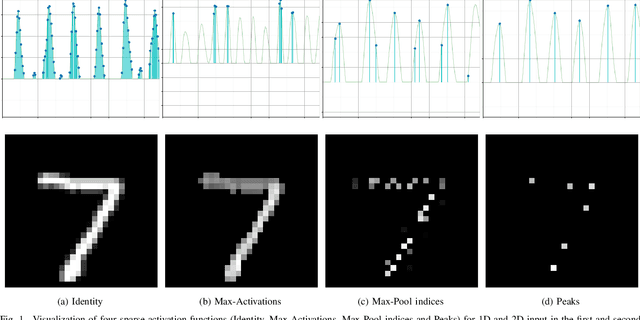
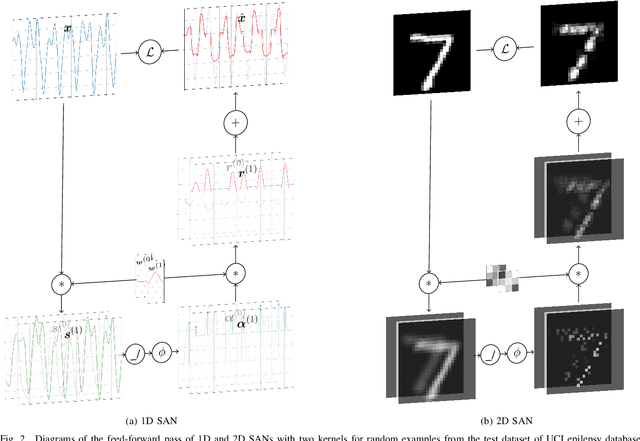
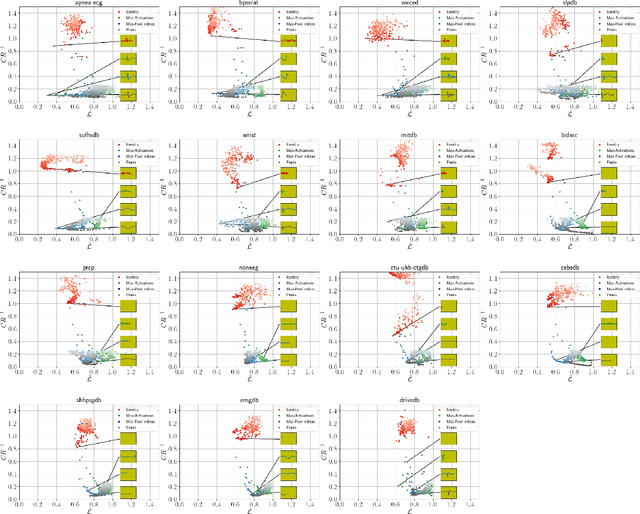
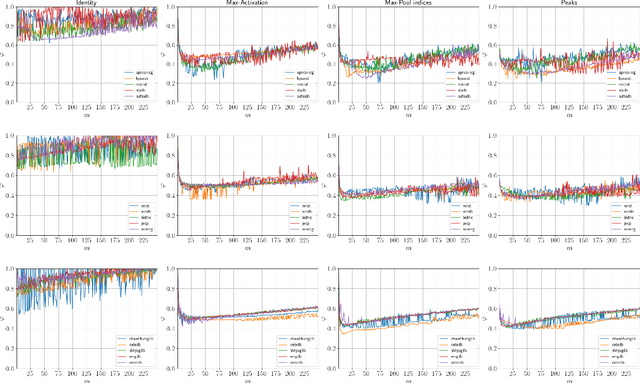
Previous literature on unsupervised learning focused on designing structural priors and optimization functions with the aim of learning meaningful features, but without considering the description length of the representations. Here we present Sparsely Activated Networks (SANs), which decompose their input as a sum of sparsely reoccurring patterns of varying amplitude, and combined with a newly proposed metric $\varphi$ they learn representations with minimal description lengths. SANs consist of kernels with shared weights that during encoding are convolved with the input and then passed through a ReLU and a sparse activation function. During decoding, the same weights are convolved with the sparse activation map and the individual reconstructions from each weight are summed to reconstruct the input. We also propose a metric $\varphi$ for model selection that favors models which combine high compression ratio and low reconstruction error and we justify its definition by exploring the hyperparameter space of SANs. We compare four sparse activation functions (Identity, Max-Activations, Max-Pool indices, Peaks) on a variety of datasets and show that SANs learn interpretable kernels that combined with $\varphi$, they minimize the description length of the representations.
Signal2Image Modules in Deep Neural Networks for EEG Classification
May 01, 2019
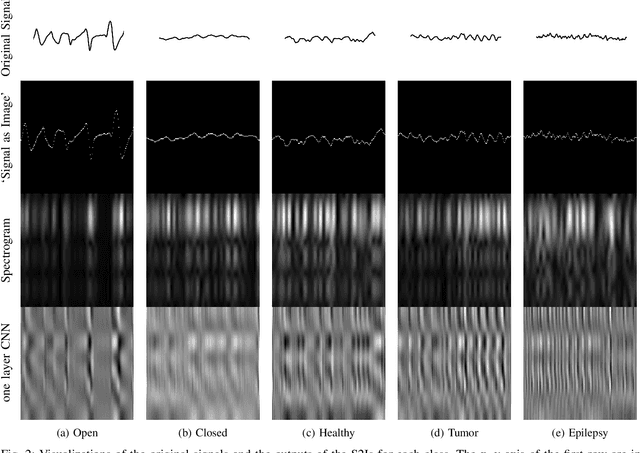
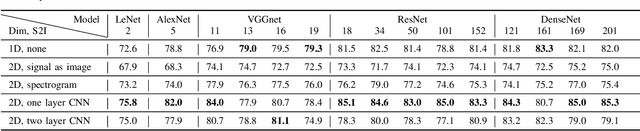
Deep learning has revolutionized computer vision utilizing the increased availability of big data and the power of parallel computational units such as graphical processing units. The vast majority of deep learning research is conducted using images as training data, however the biomedical domain is rich in physiological signals that are used for diagnosis and prediction problems. It is still an open research question how to best utilize signals to train deep neural networks. In this paper we define the term Signal2Image (S2Is) as trainable or non-trainable prefix modules that convert signals, such as Electroencephalography (EEG), to image-like representations making them suitable for training image-based deep neural networks defined as `base models'. We compare the accuracy and time performance of four S2Is (`signal as image', spectrogram, one and two layer Convolutional Neural Networks (CNNs)) combined with a set of `base models' (LeNet, AlexNet, VGGnet, ResNet, DenseNet) along with the depth-wise and 1D variations of the latter. We also provide empirical evidence that the one layer CNN S2I performs better in eleven out of fifteen tested models than non-trainable S2Is for classifying EEG signals and we present visual comparisons of the outputs of the S2Is.
Deep Learning in Cardiology
Feb 22, 2019
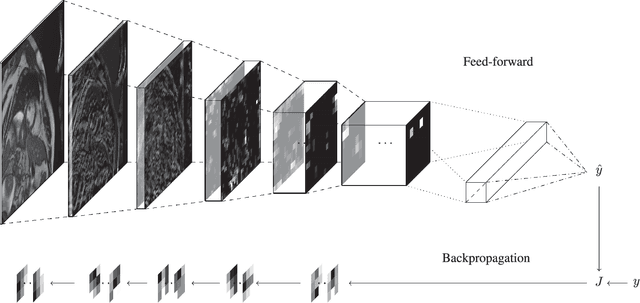

The medical field is creating large amount of data that physicians are unable to decipher and use efficiently. Moreover, rule-based expert systems are inefficient in solving complicated medical tasks or for creating insights using big data. Deep learning has emerged as a more accurate and effective technology in a wide range of medical problems such as diagnosis, prediction and intervention. Deep learning is a representation learning method that consists of layers that transform the data non-linearly, thus, revealing hierarchical relationships and structures. In this review we survey deep learning application papers that use structured data, signal and imaging modalities from cardiology. We discuss the advantages and limitations of applying deep learning in cardiology that also apply in medicine in general, while proposing certain directions as the most viable for clinical use.
* 27 pages, 2 figures, 10 tables