 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning linearly separable features for speech recognition using convolutional neural networks
Apr 16, 2015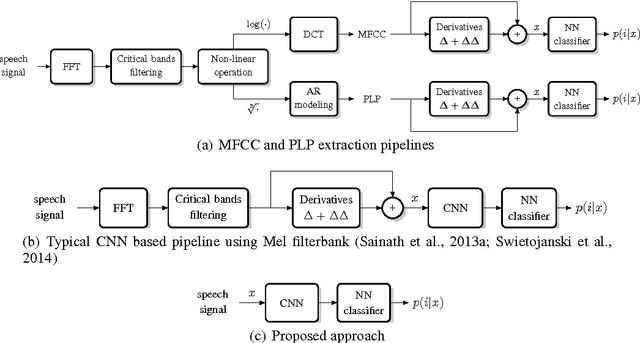
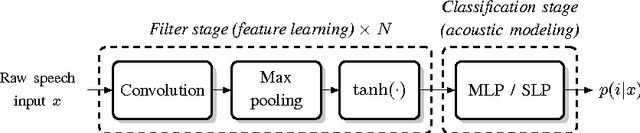
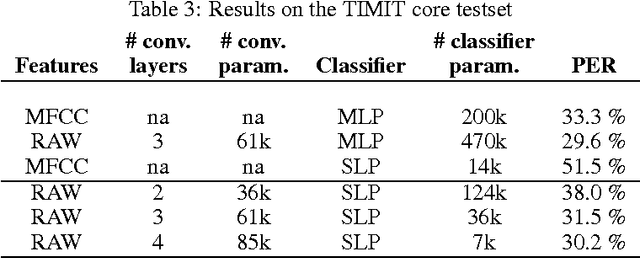
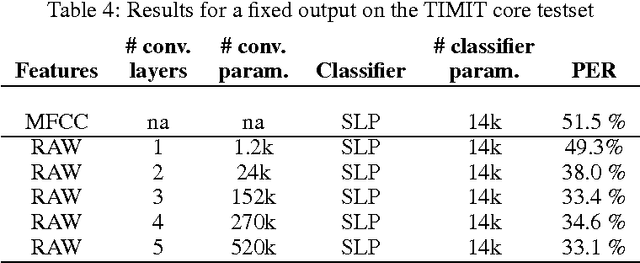
Automatic speech recognition systems usually rely on spectral-based features, such as MFCC of PLP. These features are extracted based on prior knowledge such as, speech perception or/and speech production. Recently, convolutional neural networks have been shown to be able to estimate phoneme conditional probabilities in a completely data-driven manner, i.e. using directly temporal raw speech signal as input. This system was shown to yield similar or better performance than HMM/ANN based system on phoneme recognition task and on large scale continuous speech recognition task, using less parameters. Motivated by these studies, we investigate the use of simple linear classifier in the CNN-based framework. Thus, the network learns linearly separable features from raw speech. We show that such system yields similar or better performance than MLP based system using cepstral-based features as input.
End-to-end Phoneme Sequence Recognition using Convolutional Neural Networks
Dec 07, 2013



Most phoneme recognition state-of-the-art systems rely on a classical neural network classifiers, fed with highly tuned features, such as MFCC or PLP features. Recent advances in ``deep learning'' approaches questioned such systems, but while some attempts were made with simpler features such as spectrograms, state-of-the-art systems still rely on MFCCs. This might be viewed as a kind of failure from deep learning approaches, which are often claimed to have the ability to train with raw signals, alleviating the need of hand-crafted features. In this paper, we investigate a convolutional neural network approach for raw speech signals. While convolutional architectures got tremendous success in computer vision or text processing, they seem to have been let down in the past recent years in the speech processing field. We show that it is possible to learn an end-to-end phoneme sequence classifier system directly from raw signal, with similar performance on the TIMIT and WSJ datasets than existing systems based on MFCC, questioning the need of complex hand-crafted features on large datasets.
Estimating Phoneme Class Conditional Probabilities from Raw Speech Signal using Convolutional Neural Networks
Jun 12, 2013

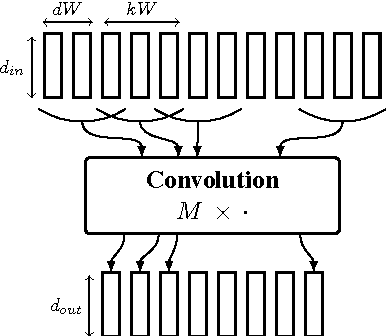
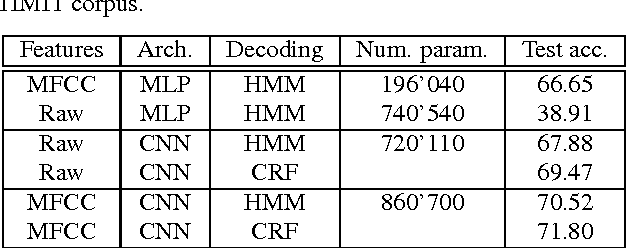
In hybrid hidden Markov model/artificial neural networks (HMM/ANN) automatic speech recognition (ASR) system, the phoneme class conditional probabilities are estimated by first extracting acoustic features from the speech signal based on prior knowledge such as, speech perception or/and speech production knowledge, and, then modeling the acoustic features with an ANN. Recent advances in machine learning techniques, more specifically in the field of image processing and text processing, have shown that such divide and conquer strategy (i.e., separating feature extraction and modeling steps) may not be necessary. Motivated from these studies, in the framework of convolutional neural networks (CNNs), this paper investigates a novel approach, where the input to the ANN is raw speech signal and the output is phoneme class conditional probability estimates. On TIMIT phoneme recognition task, we study different ANN architectures to show the benefit of CNNs and compare the proposed approach against conventional approach where, spectral-based feature MFCC is extracted and modeled by a multilayer perceptron. Our studies show that the proposed approach can yield comparable or better phoneme recognition performance when compared to the conventional approach. It indicates that CNNs can learn features relevant for phoneme classification automatically from the raw speech signal.