 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye image segmentation using visual and concept prompts with Segment Anything Model 3 (SAM3)
Mar 18, 2026Previous work has reported that vision foundation models show promising zero-shot performance in eye image segmentation. Here we examine whether the latest iteration of the Segment Anything Model, SAM3, offers better eye image segmentation performance than SAM2, and explore the performance of its new concept (text) prompting mode. Eye image segmentation performance was evaluated using diverse datasets encompassing both high-resolution high-quality videos from a lab environment and the TEyeD dataset consisting of challenging eye videos acquired in the wild. Results show that in most cases SAM3 with either visual or concept prompts did not perform better than SAM2, for both lab and in-the-wild datasets. Since SAM2 not only performed better but was also faster, we conclude that SAM2 remains the best option for eye image segmentation. We provide our adaptation of SAM3's codebase that allows processing videos of arbitrary duration.
Zero-Shot Pupil Segmentation with SAM 2: A Case Study of Over 14 Million Images
Oct 11, 2024



We explore the transformative potential of SAM 2, a vision foundation model, in advancing gaze estimation and eye tracking technologies. By significantly reducing annotation time, lowering technical barriers through its ease of deployment, and enhancing segmentation accuracy, SAM 2 addresses critical challenges faced by researchers and practitioners. Utilizing its zero-shot segmentation capabilities with minimal user input-a single click per video-we tested SAM 2 on over 14 million eye images from diverse datasets, including virtual reality setups and the world's largest unified dataset recorded using wearable eye trackers. Remarkably, in pupil segmentation tasks, SAM 2 matches the performance of domain-specific models trained solely on eye images, achieving competitive mean Intersection over Union (mIoU) scores of up to 93% without fine-tuning. Additionally, we provide our code and segmentation masks for these widely used datasets to promote further research.
Zero-Shot Segmentation of Eye Features Using the Segment Anything Model
Nov 14, 2023The advent of foundation models signals a new era in artificial intelligence. The Segment Anything Model (SAM) is the first foundation model for image segmentation. In this study, we evaluate SAM's ability to segment features from eye images recorded in virtual reality setups. The increasing requirement for annotated eye-image datasets presents a significant opportunity for SAM to redefine the landscape of data annotation in gaze estimation. Our investigation centers on SAM's zero-shot learning abilities and the effectiveness of prompts like bounding boxes or point clicks. Our results are consistent with studies in other domains, demonstrating that SAM's segmentation effectiveness can be on-par with specialized models depending on the feature, with prompts improving its performance, evidenced by an IoU of 93.34% for pupil segmentation in one dataset. Foundation models like SAM could revolutionize gaze estimation by enabling quick and easy image segmentation, reducing reliance on specialized models and extensive manual annotation.
LEyes: A Lightweight Framework for Deep Learning-Based Eye Tracking using Synthetic Eye Images
Sep 28, 2023Deep learning has bolstered gaze estimation techniques, but real-world deployment has been impeded by inadequate training datasets. This problem is exacerbated by both hardware-induced variations in eye images and inherent biological differences across the recorded participants, leading to both feature and pixel-level variance that hinders the generalizability of models trained on specific datasets. While synthetic datasets can be a solution, their creation is both time and resource-intensive. To address this problem, we present a framework called Light Eyes or "LEyes" which, unlike conventional photorealistic methods, only models key image features required for video-based eye tracking using simple light distributions. LEyes facilitates easy configuration for training neural networks across diverse gaze-estimation tasks. We demonstrate that models trained using LEyes are consistently on-par or outperform other state-of-the-art algorithms in terms of pupil and CR localization across well-known datasets. In addition, a LEyes trained model outperforms the industry standard eye tracker using significantly more cost-effective hardware. Going forward, we are confident that LEyes will revolutionize synthetic data generation for gaze estimation models, and lead to significant improvements of the next generation video-based eye trackers.
Precise localization of corneal reflections in eye images using deep learning trained on synthetic data
Apr 12, 2023We present a deep learning method for accurately localizing the center of a single corneal reflection (CR) in an eye image. Unlike previous approaches, we use a convolutional neural network (CNN) that was trained solely using simulated data. Using only simulated data has the benefit of completely sidestepping the time-consuming process of manual annotation that is required for supervised training on real eye images. To systematically evaluate the accuracy of our method, we first tested it on images with simulated CRs placed on different backgrounds and embedded in varying levels of noise. Second, we tested the method on high-quality videos captured from real eyes. Our method outperformed state-of-the-art algorithmic methods on real eye images with a 35% reduction in terms of spatial precision, and performed on par with state-of-the-art on simulated images in terms of spatial accuracy.We conclude that our method provides a precise method for CR center localization and provides a solution to the data availability problem which is one of the important common roadblocks in the development of deep learning models for gaze estimation. Due to the superior CR center localization and ease of application, our method has the potential to improve the accuracy and precision of CR-based eye trackers
Towards Situation Awareness and Attention Guidance in a Multiplayer Environment using Augmented Reality and Carcassonne
Aug 18, 2022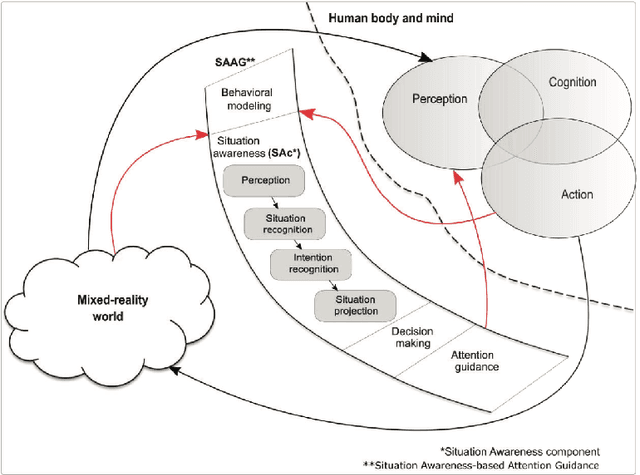

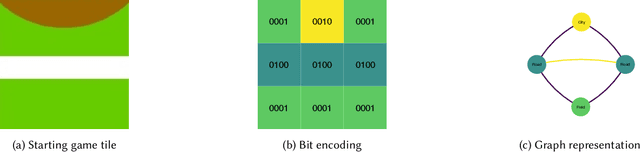
Augmented reality (AR) games are a rich environment for researching and testing computational systems that provide subtle user guidance and training. In particular computer systems that aim to augment a user's situation awareness benefit from the range of sensors and computing power available in AR headsets. In this work-in-progress paper, we present a new environment for research into situation awareness and attention guidance (SAAG): an augmented reality version of the board game Carcassonne. We also present our initial work in producing a SAAG pipeline, including the creation of game state encodings, the development and training of a gameplay AI, and the design of situation modelling and gaze tracking systems.