 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Video Question Answering: A Review of Datasets and Methods
Jan 15, 2021
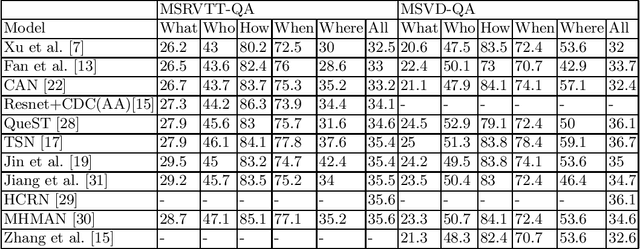


Video Question Answering (VQA) is a recent emerging challenging task in the field of Computer Vision. Several visual information retrieval techniques like Video Captioning/Description and Video-guided Machine Translation have preceded the task of VQA. VQA helps to retrieve temporal and spatial information from the video scenes and interpret it. In this survey, we review a number of methods and datasets for the task of VQA. To the best of our knowledge, no previous survey has been conducted for the VQA task.
Comparative Study of Machine Learning Models and BERT on SQuAD
May 22, 2020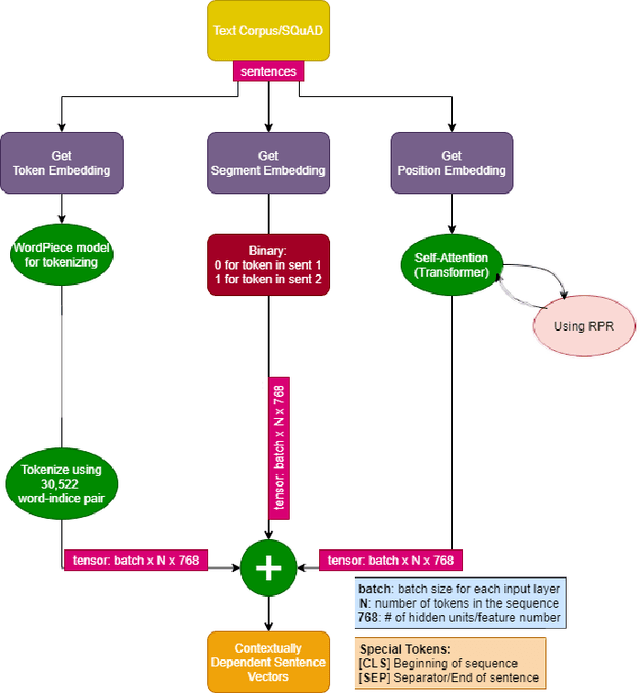
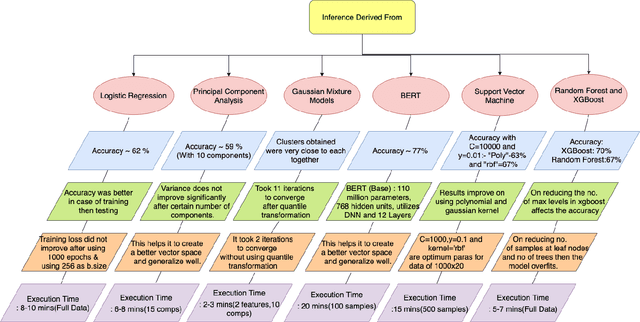
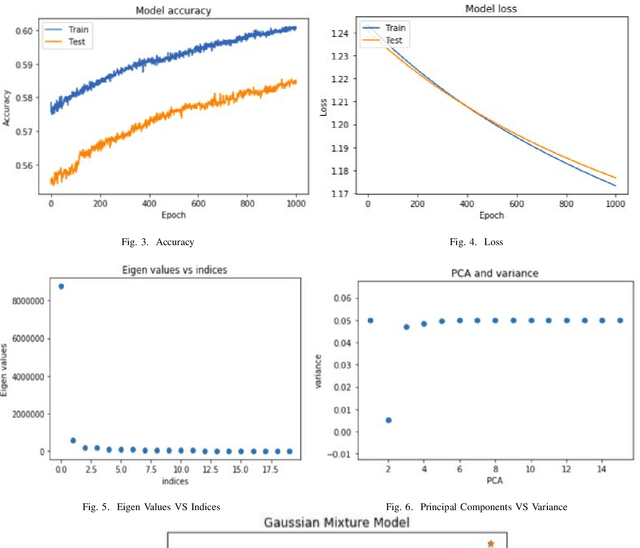
This study aims to provide a comparative analysis of performance of certain models popular in machine learning and the BERT model on the Stanford Question Answering Dataset (SQuAD). The analysis shows that the BERT model, which was once state-of-the-art on SQuAD, gives higher accuracy in comparison to other models. However, BERT requires a greater execution time even when only 100 samples are used. This shows that with increasing accuracy more amount of time is invested in training the data. Whereas in case of preliminary machine learning models, execution time for full data is lower but accuracy is compromised.