Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Study of Machine Learning Models and BERT on SQuAD
Paper and Code
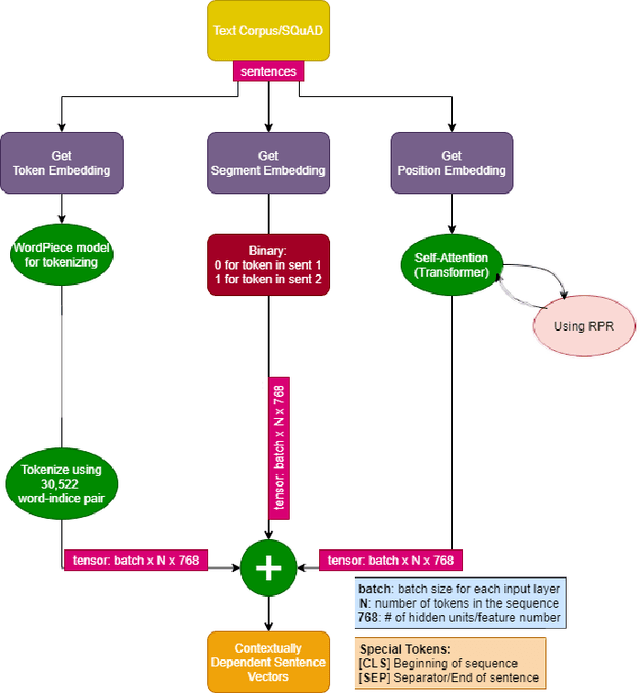
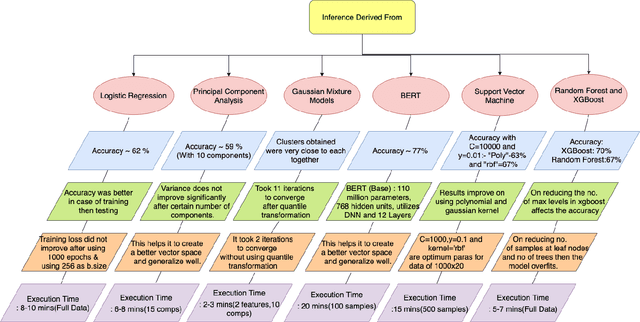
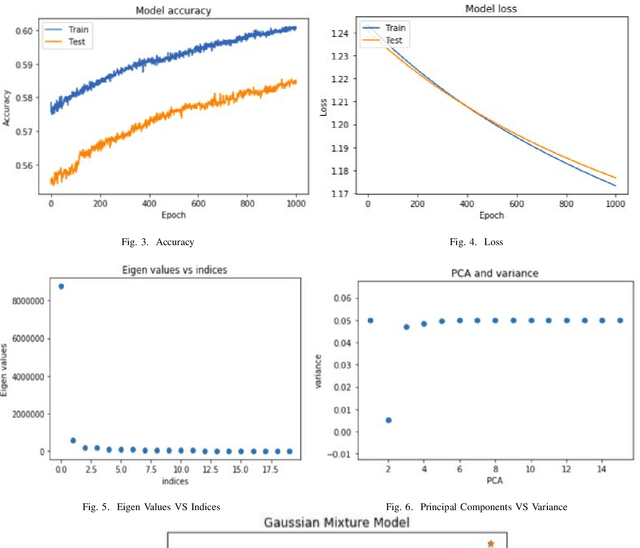
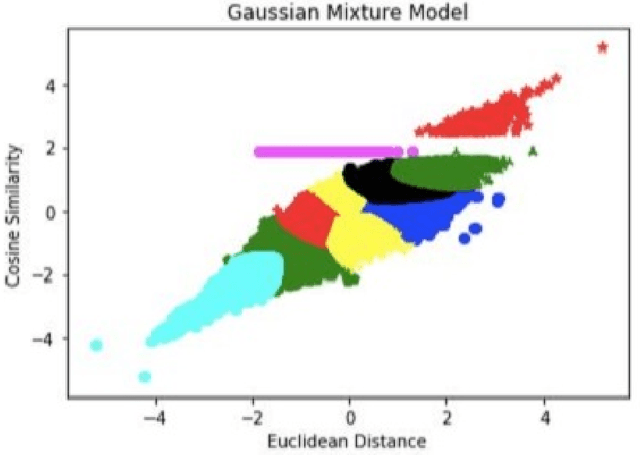
This study aims to provide a comparative analysis of performance of certain models popular in machine learning and the BERT model on the Stanford Question Answering Dataset (SQuAD). The analysis shows that the BERT model, which was once state-of-the-art on SQuAD, gives higher accuracy in comparison to other models. However, BERT requires a greater execution time even when only 100 samples are used. This shows that with increasing accuracy more amount of time is invested in training the data. Whereas in case of preliminary machine learning models, execution time for full data is lower but accuracy is compromised.
View paper on