 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCued Speech Generation Leveraging a Pre-trained Audiovisual Text-to-Speech Model
Jan 08, 2025


This paper presents a novel approach for the automatic generation of Cued Speech (ACSG), a visual communication system used by people with hearing impairment to better elicit the spoken language. We explore transfer learning strategies by leveraging a pre-trained audiovisual autoregressive text-to-speech model (AVTacotron2). This model is reprogrammed to infer Cued Speech (CS) hand and lip movements from text input. Experiments are conducted on two publicly available datasets, including one recorded specifically for this study. Performance is assessed using an automatic CS recognition system. With a decoding accuracy at the phonetic level reaching approximately 77%, the results demonstrate the effectiveness of our approach.
Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding
Jun 14, 2023



Hard of hearing or profoundly deaf people make use of cued speech (CS) as a communication tool to understand spoken language. By delivering cues that are relevant to the phonetic information, CS offers a way to enhance lipreading. In literature, there have been several studies on the dynamics between the hand and the lips in the context of human production. This article proposes a way to investigate how a neural network learns this relation for a single speaker while performing a recognition task using attention mechanisms. Further, an analysis of the learnt dynamics is utilized to establish the relationship between the two modalities and extract automatic segments. For the purpose of this study, a new dataset has been recorded for French CS. Along with the release of this dataset, a benchmark will be reported for word-level recognition, a novelty in the automatic recognition of French CS.
Multistream neural architectures for cued-speech recognition using a pre-trained visual feature extractor and constrained CTC decoding
Apr 11, 2022
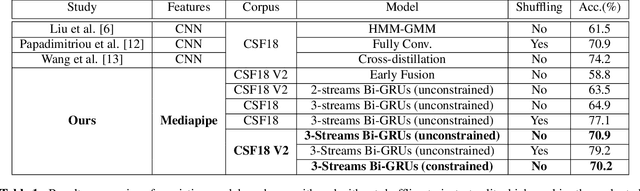
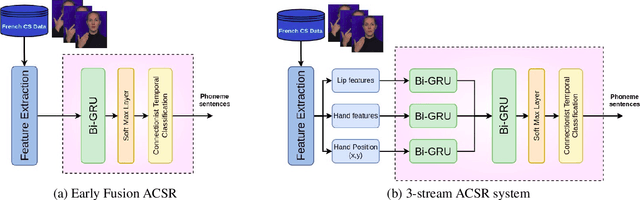
This paper proposes a simple and effective approach for automatic recognition of Cued Speech (CS), a visual communication tool that helps people with hearing impairment to understand spoken language with the help of hand gestures that can uniquely identify the uttered phonemes in complement to lipreading. The proposed approach is based on a pre-trained hand and lips tracker used for visual feature extraction and a phonetic decoder based on a multistream recurrent neural network trained with connectionist temporal classification loss and combined with a pronunciation lexicon. The proposed system is evaluated on an updated version of the French CS dataset CSF18 for which the phonetic transcription has been manually checked and corrected. With a decoding accuracy at the phonetic level of 70.88%, the proposed system outperforms our previous CNN-HMM decoder and competes with more complex baselines.