 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak Your Mind: The Speech Continuation Task as a Probe of Voice-Based Model Bias
Sep 26, 2025Speech Continuation (SC) is the task of generating a coherent extension of a spoken prompt while preserving both semantic context and speaker identity. Because SC is constrained to a single audio stream, it offers a more direct setting for probing biases in speech foundation models than dialogue does. In this work we present the first systematic evaluation of bias in SC, investigating how gender and phonation type (breathy, creaky, end-creak) affect continuation behaviour. We evaluate three recent models: SpiritLM (base and expressive), VAE-GSLM, and SpeechGPT across speaker similarity, voice quality preservation, and text-based bias metrics. Results show that while both speaker similarity and coherence remain a challenge, textual evaluations reveal significant model and gender interactions: once coherence is sufficiently high (for VAE-GSLM), gender effects emerge on text-metrics such as agency and sentence polarity. In addition, continuations revert toward modal phonation more strongly for female prompts than for male ones, revealing a systematic voice-quality bias. These findings highlight SC as a controlled probe of socially relevant representational biases in speech foundation models, and suggest that it will become an increasingly informative diagnostic as continuation quality improves.
Fill in the Gap! Combining Self-supervised Representation Learning with Neural Audio Synthesis for Speech Inpainting
May 30, 2024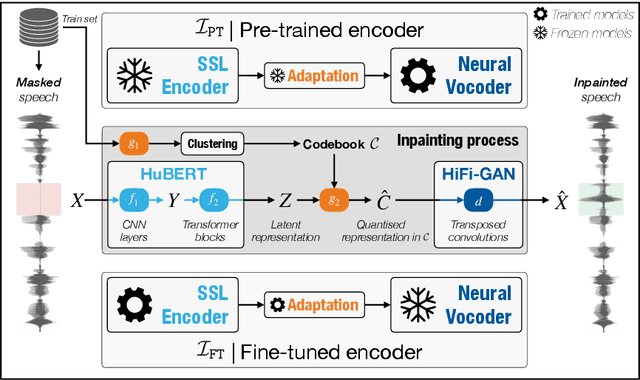
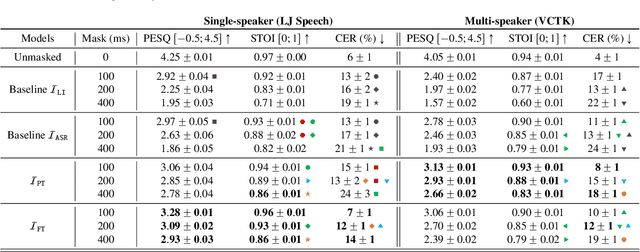
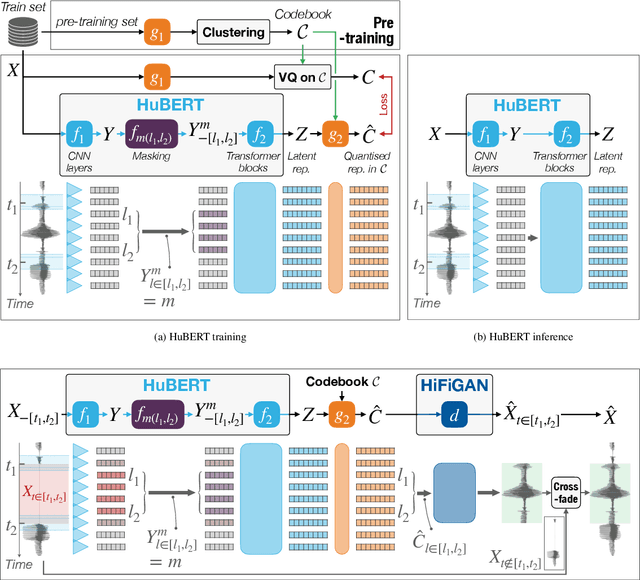
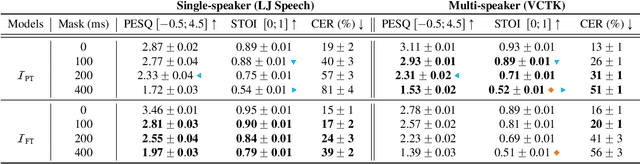
Most speech self-supervised learning (SSL) models are trained with a pretext task which consists in predicting missing parts of the input signal, either future segments (causal prediction) or segments masked anywhere within the input (non-causal prediction). Learned speech representations can then be efficiently transferred to downstream tasks (e.g., automatic speech or speaker recognition). In the present study, we investigate the use of a speech SSL model for speech inpainting, that is reconstructing a missing portion of a speech signal from its surrounding context, i.e., fulfilling a downstream task that is very similar to the pretext task. To that purpose, we combine an SSL encoder, namely HuBERT, with a neural vocoder, namely HiFiGAN, playing the role of a decoder. In particular, we propose two solutions to match the HuBERT output with the HiFiGAN input, by freezing one and fine-tuning the other, and vice versa. Performance of both approaches was assessed in single- and multi-speaker settings, for both informed and blind inpainting configurations (i.e., the position of the mask is known or unknown, respectively), with different objective metrics and a perceptual evaluation. Performances show that if both solutions allow to correctly reconstruct signal portions up to the size of 200ms (and even 400ms in some cases), fine-tuning the SSL encoder provides a more accurate signal reconstruction in the single-speaker setting case, while freezing it (and training the neural vocoder instead) is a better strategy when dealing with multi-speaker data.
Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding
Jun 14, 2023



Hard of hearing or profoundly deaf people make use of cued speech (CS) as a communication tool to understand spoken language. By delivering cues that are relevant to the phonetic information, CS offers a way to enhance lipreading. In literature, there have been several studies on the dynamics between the hand and the lips in the context of human production. This article proposes a way to investigate how a neural network learns this relation for a single speaker while performing a recognition task using attention mechanisms. Further, an analysis of the learnt dynamics is utilized to establish the relationship between the two modalities and extract automatic segments. For the purpose of this study, a new dataset has been recorded for French CS. Along with the release of this dataset, a benchmark will be reported for word-level recognition, a novelty in the automatic recognition of French CS.