 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Medical Image Segmentation with Advanced Decoder Design
Oct 05, 2024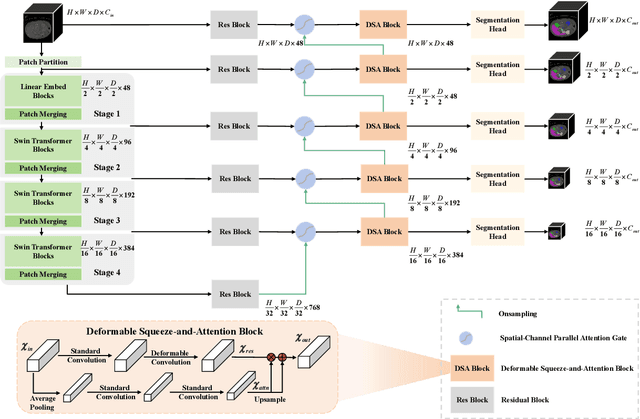
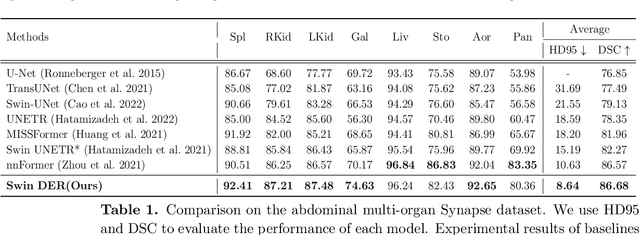
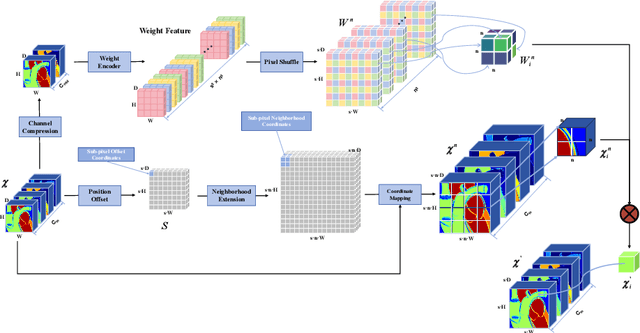

U-Net is widely used in medical image segmentation due to its simple and flexible architecture design. To address the challenges of scale and complexity in medical tasks, several variants of U-Net have been proposed. In particular, methods based on Vision Transformer (ViT), represented by Swin UNETR, have gained widespread attention in recent years. However, these improvements often focus on the encoder, overlooking the crucial role of the decoder in optimizing segmentation details. This design imbalance limits the potential for further enhancing segmentation performance. To address this issue, we analyze the roles of various decoder components, including upsampling method, skip connection, and feature extraction module, as well as the shortcomings of existing methods. Consequently, we propose Swin DER (i.e., Swin UNETR Decoder Enhanced and Refined) by specifically optimizing the design of these three components. Swin DER performs upsampling using learnable interpolation algorithm called offset coordinate neighborhood weighted up sampling (Onsampling) and replaces traditional skip connection with spatial-channel parallel attention gate (SCP AG). Additionally, Swin DER introduces deformable convolution along with attention mechanism in the feature extraction module of the decoder. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and the MSD brain tumor segmentation task. Code is available at: https://github.com/WillBeanYang/Swin-DER
More complex encoder is not all you need
Sep 21, 2023


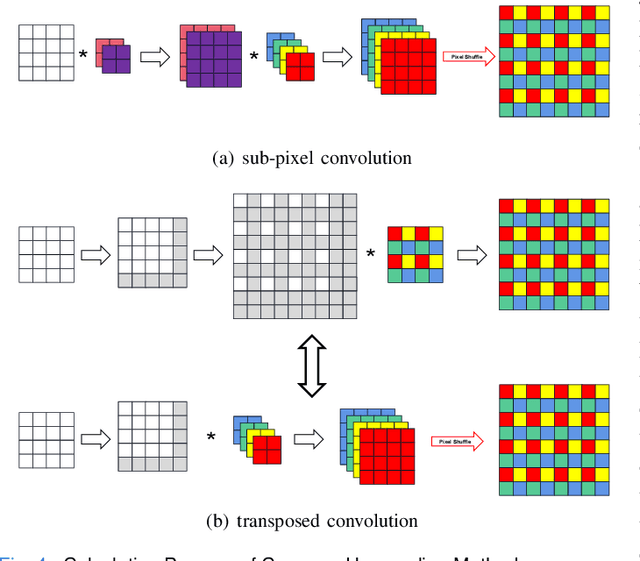
U-Net and its variants have been widely used in medical image segmentation. However, most current U-Net variants confine their improvement strategies to building more complex encoder, while leaving the decoder unchanged or adopting a simple symmetric structure. These approaches overlook the true functionality of the decoder: receiving low-resolution feature maps from the encoder and restoring feature map resolution and lost information through upsampling. As a result, the decoder, especially its upsampling component, plays a crucial role in enhancing segmentation outcomes. However, in 3D medical image segmentation, the commonly used transposed convolution can result in visual artifacts. This issue stems from the absence of direct relationship between adjacent pixels in the output feature map. Furthermore, plain encoder has already possessed sufficient feature extraction capability because downsampling operation leads to the gradual expansion of the receptive field, but the loss of information during downsampling process is unignorable. To address the gap in relevant research, we extend our focus beyond the encoder and introduce neU-Net (i.e., not complex encoder U-Net), which incorporates a novel Sub-pixel Convolution for upsampling to construct a powerful decoder. Additionally, we introduce multi-scale wavelet inputs module on the encoder side to provide additional information. Our model design achieves excellent results, surpassing other state-of-the-art methods on both the Synapse and ACDC datasets.