 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRNet: Semi-Supervised Semantic Segmentation Via Label Reuse for Human Decomposition Images
Feb 24, 2022

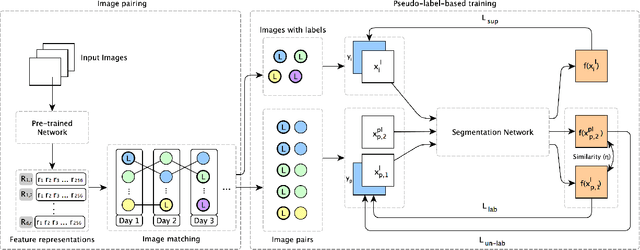
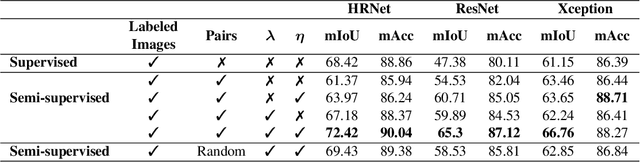
Semantic segmentation is a challenging computer vision task demanding a significant amount of pixel-level annotated data. Producing such data is a time-consuming and costly process, especially for domains with a scarcity of experts, such as medicine or forensic anthropology. While numerous semi-supervised approaches have been developed to make the most from the limited labeled data and ample amount of unlabeled data, domain-specific real-world datasets often have characteristics that both reduce the effectiveness of off-the-shelf state-of-the-art methods and also provide opportunities to create new methods that exploit these characteristics. We propose and evaluate a semi-supervised method that reuses available labels for unlabeled images of a dataset by exploiting existing similarities, while dynamically weighting the impact of these reused labels in the training process. We evaluate our method on a large dataset of human decomposition images and find that our method, while conceptually simple, outperforms state-of-the-art consistency and pseudo-labeling-based methods for the segmentation of this dataset. This paper includes graphic content of human decomposition.
Pseudo Pixel-level Labeling for Images with Evolving Content
May 20, 2021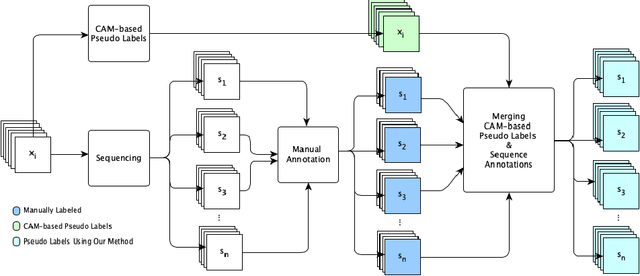
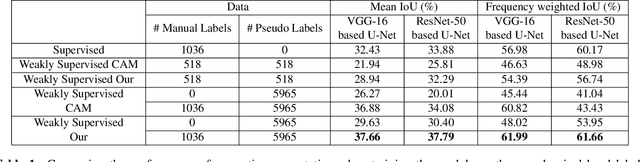

Annotating images for semantic segmentation requires intense manual labor and is a time-consuming and expensive task especially for domains with a scarcity of experts, such as Forensic Anthropology. We leverage the evolving nature of images depicting the decay process in human decomposition data to design a simple yet effective pseudo-pixel-level label generation technique to reduce the amount of effort for manual annotation of such images. We first identify sequences of images with a minimum variation that are most suitable to share the same or similar annotation using an unsupervised approach. Given one user-annotated image in each sequence, we propagate the annotation to the remaining images in the sequence by merging it with annotations produced by a state-of-the-art CAM-based pseudo label generation technique. To evaluate the quality of our pseudo-pixel-level labels, we train two semantic segmentation models with VGG and ResNet backbones on images labeled using our pseudo labeling method and those of a state-of-the-art method. The results indicate that using our pseudo-labels instead of those generated using the state-of-the-art method in the training process improves the mean-IoU and the frequency-weighted-IoU of the VGG and ResNet-based semantic segmentation models by 3.36%, 2.58%, 10.39%, and 12.91% respectively.
Collaborative Learning of Semi-Supervised Clustering and Classification for Labeling Uncurated Data
Mar 09, 2020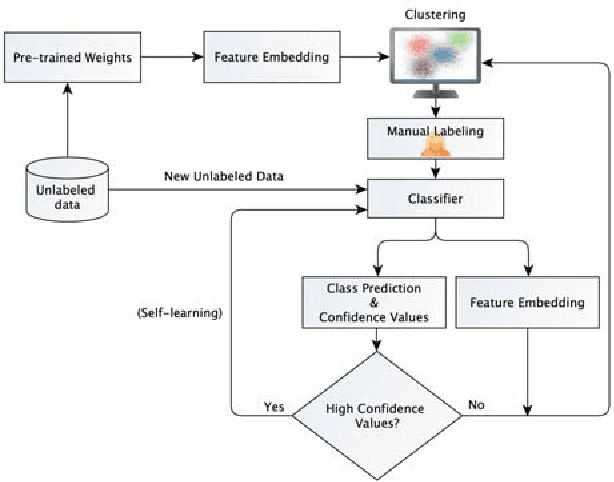
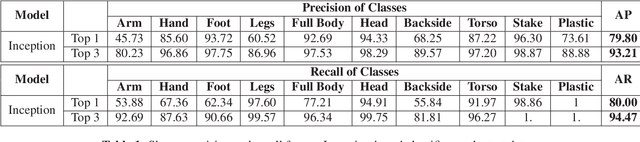

Domain-specific image collections present potential value in various areas of science and business but are often not curated nor have any way to readily extract relevant content. To employ contemporary supervised image analysis methods on such image data, they must first be cleaned and organized, and then manually labeled for the nomenclature employed in the specific domain, which is a time consuming and expensive endeavor. To address this issue, we designed and implemented the Plud system. Plud provides an iterative semi-supervised workflow to minimize the effort spent by an expert and handles realistic large collections of images. We believe it can support labeling datasets regardless of their size and type. Plud is an iterative sequence of unsupervised clustering, human assistance, and supervised classification. With each iteration 1) the labeled dataset grows, 2) the generality of the classification method and its accuracy increases, and 3) manual effort is reduced. We evaluated the effectiveness of our system, by applying it on over a million images documenting human decomposition. In our experiment comparing manual labeling with labeling conducted with the support of Plud, we found that it reduces the time needed to label data and produces highly accurate models for this new domain.
An Analytical Workflow for Clustering Forensic Images
Dec 29, 2019
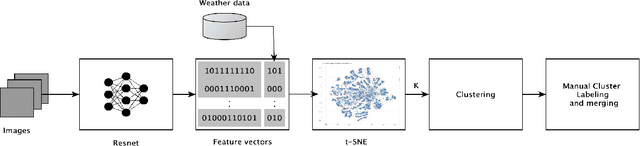
Large collections of images, if curated, drastically contribute to the quality of research in many domains. Unsupervised clustering is an intuitive, yet effective step towards curating such datasets. In this work, we present a workflow for unsupervisedly clustering a large collection of forensic images. The workflow utilizes classic clustering on deep feature representation of the images in addition to domain-related data to group them together. Our manual evaluation shows a purity of 89\% for the resulted clusters.