 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Learning of Semi-Supervised Clustering and Classification for Labeling Uncurated Data
Paper and Code
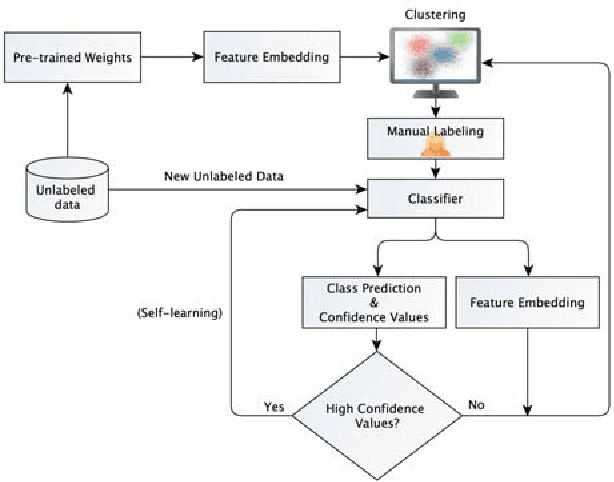
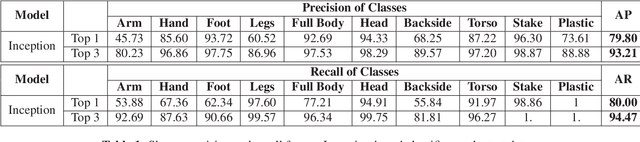

Domain-specific image collections present potential value in various areas of science and business but are often not curated nor have any way to readily extract relevant content. To employ contemporary supervised image analysis methods on such image data, they must first be cleaned and organized, and then manually labeled for the nomenclature employed in the specific domain, which is a time consuming and expensive endeavor. To address this issue, we designed and implemented the Plud system. Plud provides an iterative semi-supervised workflow to minimize the effort spent by an expert and handles realistic large collections of images. We believe it can support labeling datasets regardless of their size and type. Plud is an iterative sequence of unsupervised clustering, human assistance, and supervised classification. With each iteration 1) the labeled dataset grows, 2) the generality of the classification method and its accuracy increases, and 3) manual effort is reduced. We evaluated the effectiveness of our system, by applying it on over a million images documenting human decomposition. In our experiment comparing manual labeling with labeling conducted with the support of Plud, we found that it reduces the time needed to label data and produces highly accurate models for this new domain.