 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRNet: Semi-Supervised Semantic Segmentation Via Label Reuse for Human Decomposition Images
Feb 24, 2022

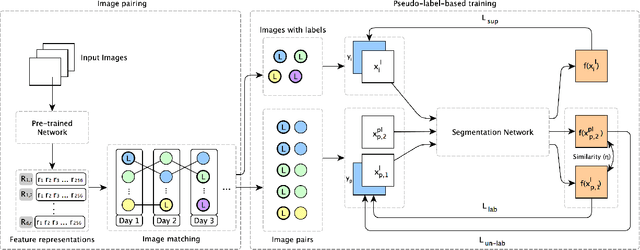
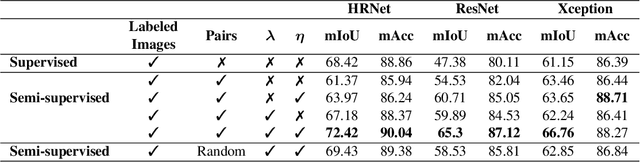
Semantic segmentation is a challenging computer vision task demanding a significant amount of pixel-level annotated data. Producing such data is a time-consuming and costly process, especially for domains with a scarcity of experts, such as medicine or forensic anthropology. While numerous semi-supervised approaches have been developed to make the most from the limited labeled data and ample amount of unlabeled data, domain-specific real-world datasets often have characteristics that both reduce the effectiveness of off-the-shelf state-of-the-art methods and also provide opportunities to create new methods that exploit these characteristics. We propose and evaluate a semi-supervised method that reuses available labels for unlabeled images of a dataset by exploiting existing similarities, while dynamically weighting the impact of these reused labels in the training process. We evaluate our method on a large dataset of human decomposition images and find that our method, while conceptually simple, outperforms state-of-the-art consistency and pseudo-labeling-based methods for the segmentation of this dataset. This paper includes graphic content of human decomposition.
Pseudo Pixel-level Labeling for Images with Evolving Content
May 20, 2021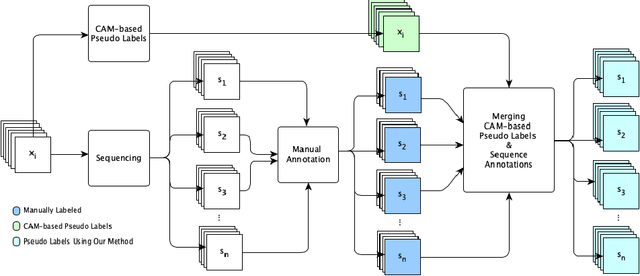
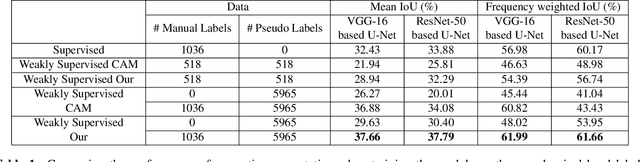

Annotating images for semantic segmentation requires intense manual labor and is a time-consuming and expensive task especially for domains with a scarcity of experts, such as Forensic Anthropology. We leverage the evolving nature of images depicting the decay process in human decomposition data to design a simple yet effective pseudo-pixel-level label generation technique to reduce the amount of effort for manual annotation of such images. We first identify sequences of images with a minimum variation that are most suitable to share the same or similar annotation using an unsupervised approach. Given one user-annotated image in each sequence, we propagate the annotation to the remaining images in the sequence by merging it with annotations produced by a state-of-the-art CAM-based pseudo label generation technique. To evaluate the quality of our pseudo-pixel-level labels, we train two semantic segmentation models with VGG and ResNet backbones on images labeled using our pseudo labeling method and those of a state-of-the-art method. The results indicate that using our pseudo-labels instead of those generated using the state-of-the-art method in the training process improves the mean-IoU and the frequency-weighted-IoU of the VGG and ResNet-based semantic segmentation models by 3.36%, 2.58%, 10.39%, and 12.91% respectively.