 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of Loss Functions to Improve Generalizability of Deep Metric Learning methods
Jul 02, 2021



Deep Metric Learning (DML) learns a non-linear semantic embedding from input data that brings similar pairs together while keeps dissimilar data away from each other. To this end, many different methods are proposed in the last decade with promising results in various applications. The success of a DML algorithm greatly depends on its loss function. However, no loss function is perfect, and it deals only with some aspects of an optimal similarity embedding. Besides, the generalizability of the DML on unseen categories during the test stage is an important matter that is not considered by existing loss functions. To address these challenges, we propose novel approaches to combine different losses built on top of a shared deep feature extractor. The proposed ensemble of losses enforces the deep model to extract features that are consistent with all losses. Since the selected losses are diverse and each emphasizes different aspects of an optimal semantic embedding, our effective combining methods yield a considerable improvement over any individual loss and generalize well on unseen categories. Here, there is no limitation in choosing loss functions, and our methods can work with any set of existing ones. Besides, they can optimize each loss function as well as its weight in an end-to-end paradigm with no need to adjust any hyper-parameter. We evaluate our methods on some popular datasets from the machine vision domain in conventional Zero-Shot-Learning (ZSL) settings. The results are very encouraging and show that our methods outperform all baseline losses by a large margin in all datasets.
A Framework to Enhance Generalization of Deep Metric Learning methods using General Discriminative Feature Learning and Class Adversarial Neural Networks
Jun 11, 2021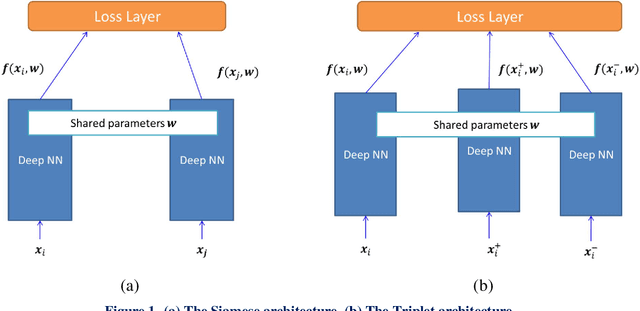
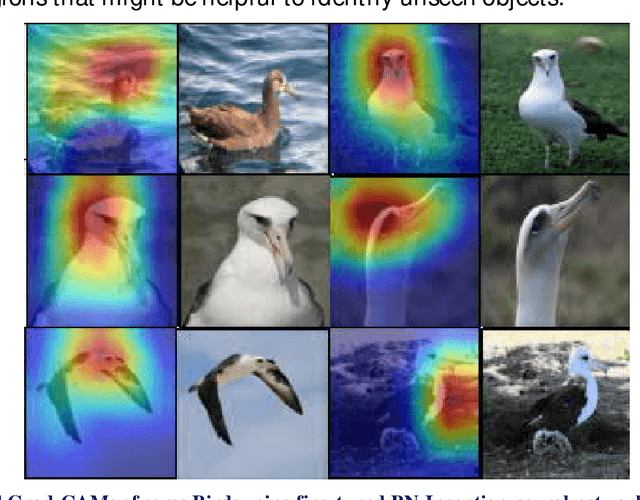

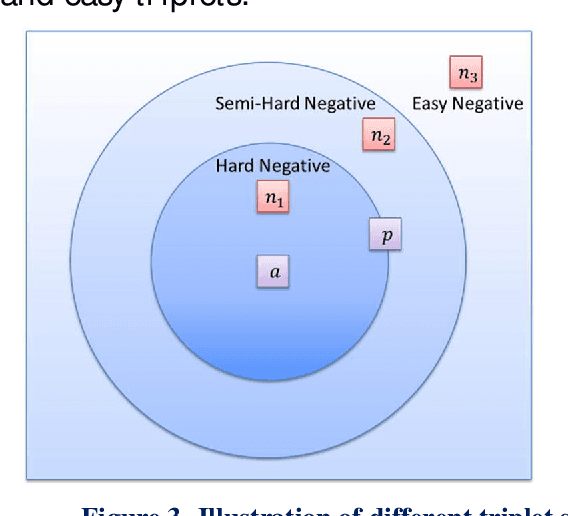
Metric learning algorithms aim to learn a distance function that brings the semantically similar data items together and keeps dissimilar ones at a distance. The traditional Mahalanobis distance learning is equivalent to find a linear projection. In contrast, Deep Metric Learning (DML) methods are proposed that automatically extract features from data and learn a non-linear transformation from input space to a semantically embedding space. Recently, many DML methods are proposed focused to enhance the discrimination power of the learned metric by providing novel sampling strategies or loss functions. This approach is very helpful when both the training and test examples are coming from the same set of categories. However, it is less effective in many applications of DML such as image retrieval and person-reidentification. Here, the DML should learn general semantic concepts from observed classes and employ them to rank or identify objects from unseen categories. Neglecting the generalization ability of the learned representation and just emphasizing to learn a more discriminative embedding on the observed classes may lead to the overfitting problem. To address this limitation, we propose a framework to enhance the generalization power of existing DML methods in a Zero-Shot Learning (ZSL) setting by general yet discriminative representation learning and employing a class adversarial neural network. To learn a more general representation, we propose to employ feature maps of intermediate layers in a deep neural network and enhance their discrimination power through an attention mechanism. Besides, a class adversarial network is utilized to enforce the deep model to seek class invariant features for the DML task. We evaluate our work on widely used machine vision datasets in a ZSL setting.
Low-Rank Robust Online Distance/Similarity Learning based on the Rescaled Hinge Loss
Oct 10, 2020



An important challenge in metric learning is scalability to both size and dimension of input data. Online metric learning algorithms are proposed to address this challenge. Existing methods are commonly based on (Passive Aggressive) PA approach. Hence, they can rapidly process large volumes of data with an adaptive learning rate. However, these algorithms are based on the Hinge loss and so are not robust against outliers and label noise. Also, existing online methods usually assume training triplets or pairwise constraints are exist in advance. However, many datasets in real-world applications are in the form of input data and their associated labels. We address these challenges by formulating the online Distance-Similarity learning problem with the robust Rescaled hinge loss function. The proposed model is rather general and can be applied to any PA-based online Distance-Similarity algorithm. Also, we develop an efficient robust one-pass triplet construction algorithm. Finally, to provide scalability in high dimensional DML environments, the low-rank version of the proposed methods is presented that not only reduces the computational cost significantly but also keeps the predictive performance of the learned metrics. Also, it provides a straightforward extension of our methods for deep Distance-Similarity learning. We conduct several experiments on datasets from various applications. The results confirm that the proposed methods significantly outperform state-of-the-art online DML methods in the presence of label noise and outliers by a large margin.
Robust Metric Learning based on the Rescaled Hinge Loss
Apr 26, 2019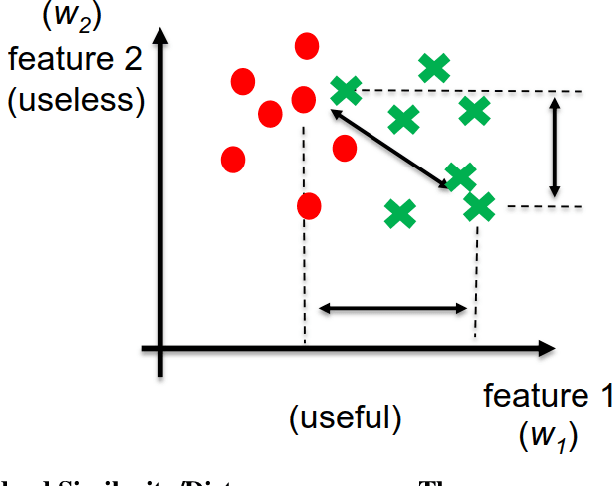
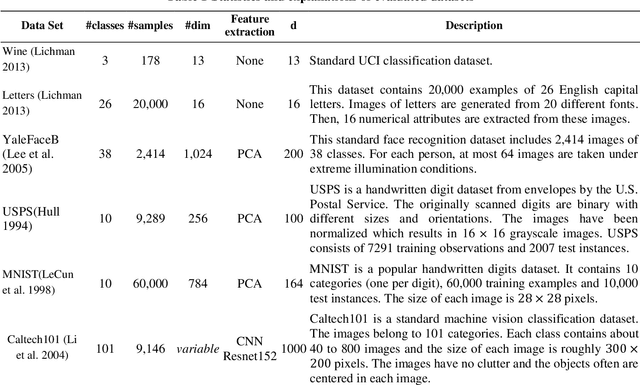
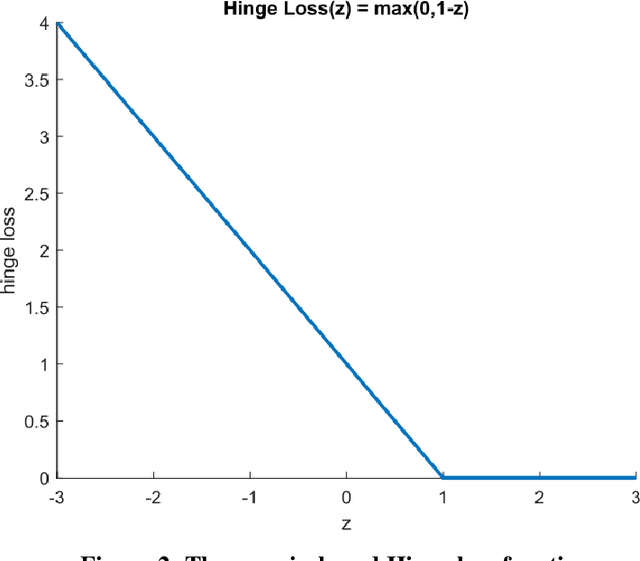

Distance/Similarity learning is a fundamental problem in machine learning. For example, kNN classifier or clustering methods are based on a distance/similarity measure. Metric learning algorithms enhance the efficiency of these methods by learning an optimal distance function from data. Most metric learning methods need training information in the form of pair or triplet sets. Nowadays, this training information often is obtained from the Internet via crowdsourcing methods. Therefore, this information may contain label noise or outliers leading to the poor performance of the learned metric. It is even possible that the learned metric functions perform worse than the general metrics such as Euclidean distance. To address this challenge, this paper presents a new robust metric learning method based on the Rescaled Hinge loss. This loss function is a general case of the popular Hinge loss and initially introduced in (Xu et al. 2017) to develop a new robust SVM algorithm. In this paper, we formulate the metric learning problem using the Rescaled Hinge loss function and then develop an efficient algorithm based on HQ (Half-Quadratic) to solve the problem. Experimental results on a variety of both real and synthetic datasets confirm that our new robust algorithm considerably outperforms state-of-the-art metric learning methods in the presence of label noise and outliers.
Large Scale Local Online Similarity/Distance Learning Framework based on Passive/Aggressive
Apr 05, 2018



Similarity/Distance measures play a key role in many machine learning, pattern recognition, and data mining algorithms, which leads to the emergence of metric learning field. Many metric learning algorithms learn a global distance function from data that satisfy the constraints of the problem. However, in many real-world datasets that the discrimination power of features varies in the different regions of input space, a global metric is often unable to capture the complexity of the task. To address this challenge, local metric learning methods are proposed that learn multiple metrics across the different regions of input space. Some advantages of these methods are high flexibility and the ability to learn a nonlinear mapping but typically achieves at the expense of higher time requirement and overfitting problem. To overcome these challenges, this research presents an online multiple metric learning framework. Each metric in the proposed framework is composed of a global and a local component learned simultaneously. Adding a global component to a local metric efficiently reduce the problem of overfitting. The proposed framework is also scalable with both sample size and the dimension of input data. To the best of our knowledge, this is the first local online similarity/distance learning framework based on PA (Passive/Aggressive). In addition, for scalability with the dimension of input data, DRP (Dual Random Projection) is extended for local online learning in the present work. It enables our methods to be run efficiently on high-dimensional datasets, while maintains their predictive performance. The proposed framework provides a straightforward local extension to any global online similarity/distance learning algorithm based on PA.