 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScattering Networks on Noncommutative Finite Groups
May 27, 2025



Scattering Networks were initially designed to elucidate the behavior of early layers in Convolutional Neural Networks (CNNs) over Euclidean spaces and are grounded in wavelets. In this work, we introduce a scattering transform on an arbitrary finite group (not necessarily abelian) within the context of group-equivariant convolutional neural networks (G-CNNs). We present wavelets on finite groups and analyze their similarity to classical wavelets. We demonstrate that, under certain conditions in the wavelet coefficients, the scattering transform is non-expansive, stable under deformations, preserves energy, equivariant with respect to left and right group translations, and, as depth increases, the scattering coefficients are less sensitive to group translations of the signal, all desirable properties of convolutional neural networks. Furthermore, we provide examples illustrating the application of the scattering transform to classify data with domains involving abelian and nonabelian groups.
Centrally Coordinated Multi-Agent Reinforcement Learning for Power Grid Topology Control
Feb 12, 2025Power grid operation is becoming more complex due to the increase in generation of renewable energy. The recent series of Learning To Run a Power Network (L2RPN) competitions have encouraged the use of artificial agents to assist human dispatchers in operating power grids. However, the combinatorial nature of the action space poses a challenge to both conventional optimizers and learned controllers. Action space factorization, which breaks down decision-making into smaller sub-tasks, is one approach to tackle the curse of dimensionality. In this study, we propose a centrally coordinated multi-agent (CCMA) architecture for action space factorization. In this approach, regional agents propose actions and subsequently a coordinating agent selects the final action. We investigate several implementations of the CCMA architecture, and benchmark in different experimental settings against various L2RPN baseline approaches. The CCMA architecture exhibits higher sample efficiency and superior final performance than the baseline approaches. The results suggest high potential of the CCMA approach for further application in higher-dimensional L2RPN as well as real-world power grid settings.
Is Stochastic Gradient Descent Effective? A PDE Perspective on Machine Learning processes
Jan 14, 2025In this paper we analyze the behaviour of the stochastic gradient descent (SGD), a widely used method in supervised learning for optimizing neural network weights via a minimization of non-convex loss functions. Since the pioneering work of E, Li and Tai (2017), the underlying structure of such processes can be understood via parabolic PDEs of Fokker-Planck type, which are at the core of our analysis. Even if Fokker-Planck equations have a long history and a extensive literature, almost nothing is known when the potential is non-convex or when the diffusion matrix is degenerate, and this is the main difficulty that we face in our analysis. We identify two different regimes: in the initial phase of SGD, the loss function drives the weights to concentrate around the nearest local minimum. We refer to this phase as the drift regime and we provide quantitative estimates on this concentration phenomenon. Next, we introduce the diffusion regime, where stochastic fluctuations help the learning process to escape suboptimal local minima. We analyze the Mean Exit Time (MET) and prove upper and lower bounds of the MET. Finally, we address the asymptotic convergence of SGD, for a non-convex cost function and a degenerate diffusion matrix, that do not allow to use the standard approaches, and require new techniques. For this purpose, we exploit two different methods: duality and entropy methods. We provide new results about the dynamics and effectiveness of SGD, offering a deep connection between stochastic optimization and PDE theory, and some answers and insights to basic questions in the Machine Learning processes: How long does SGD take to escape from a bad minimum? Do neural network parameters converge using SGD? How do parameters evolve in the first stage of training with SGD?
Learning optimal smooth invariant subspaces for data approximation
Nov 21, 2023

In this article, we consider the problem of approximating a finite set of data (usually huge in applications) by invariant subspaces generated through a small set of smooth functions. The invariance is either by translations under a full-rank lattice or through the action of crystallographic groups. Smoothness is ensured by stipulating that the generators belong to a Paley-Wiener space, that is selected in an optimal way based on the characteristics of the given data. To complete our investigation, we analyze the fundamental role played by the lattice in the process of approximation.
Reconstructing group wavelet transform from feature maps with a reproducing kernel iteration
Oct 01, 2021



In this paper we consider the problem of reconstructing an image that is downsampled in the space of its $SE(2)$ wavelet transform, which is motivated by classical models of simple cells receptive fields and feature preference maps in primary visual cortex. We prove that, whenever the problem is solvable, the reconstruction can be obtained by an elementary project and replace iterative scheme based on the reproducing kernel arising from the group structure, and show numerical results on real images.
Optimal translational-rotational invariant dictionaries for images
Sep 04, 2019
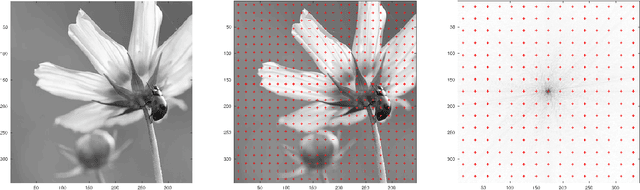
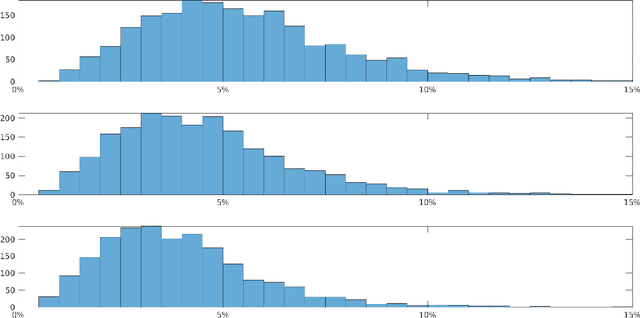
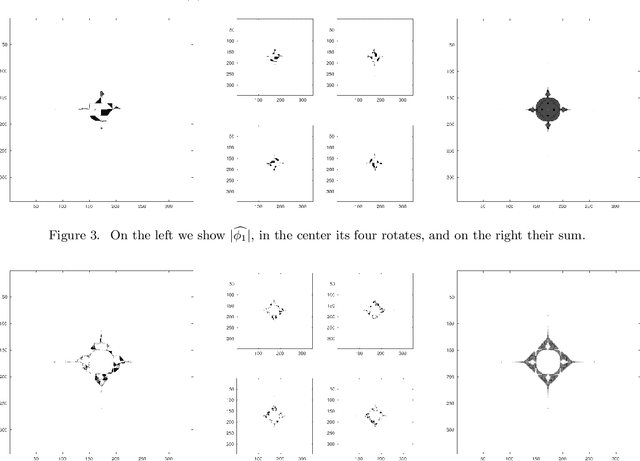
We provide the construction of a set of square matrices whose translates and rotates provide a Parseval frame that is optimal for approximating a given dataset of images. Our approach is based on abstract harmonic analysis techniques. Optimality is considered with respect to the quadratic error of approximation of the images in the dataset with their projection onto a linear subspace that is invariant under translations and rotations. In addition, we provide an elementary and fully self-contained proof of optimality, and the numerical results from datasets of natural images.
Geometry and dimensionality reduction of feature spaces in primary visual cortex
Sep 14, 2015Some geometric properties of the wavelet analysis performed by visual neurons are discussed and compared with experimental data. In particular, several relationships between the cortical morphologies and the parametric dependencies of extracted features are formalized and considered from a harmonic analysis point of view.
Cortical spatio-temporal dimensionality reduction for visual grouping
Oct 03, 2014The visual systems of many mammals, including humans, is able to integrate the geometric information of visual stimuli and to perform cognitive tasks already at the first stages of the cortical processing. This is thought to be the result of a combination of mechanisms, which include feature extraction at single cell level and geometric processing by means of cells connectivity. We present a geometric model of such connectivities in the space of detected features associated to spatio-temporal visual stimuli, and show how they can be used to obtain low-level object segmentation. The main idea is that of defining a spectral clustering procedure with anisotropic affinities over datasets consisting of embeddings of the visual stimuli into higher dimensional spaces. Neural plausibility of the proposed arguments will be discussed.