 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning Using Only Peer Assessment
Oct 10, 2019
This paper considers a variant of the classical online learning problem with expert predictions. Our model's differences and challenges are due to lacking any direct feedback on the loss each expert incurs at each time step $t$. We propose an approach that uses peer assessment and identify conditions where it succeeds. Our techniques revolve around a carefully designed peer score function $s()$ that scores experts' predictions based on the peer consensus. We show a sufficient condition, that we call \emph{peer calibration}, under which standard online learning algorithms using loss feedback computed by the carefully crafted $s()$ have bounded regret with respect to the unrevealed ground truth values. We then demonstrate how suitable $s()$ functions can be derived for different assumptions and models.
Gradient descent with identity initialization efficiently learns positive definite linear transformations by deep residual networks
Jun 18, 2018We analyze algorithms for approximating a function $f(x) = \Phi x$ mapping $\Re^d$ to $\Re^d$ using deep linear neural networks, i.e. that learn a function $h$ parameterized by matrices $\Theta_1,...,\Theta_L$ and defined by $h(x) = \Theta_L \Theta_{L-1} ... \Theta_1 x$. We focus on algorithms that learn through gradient descent on the population quadratic loss in the case that the distribution over the inputs is isotropic. We provide polynomial bounds on the number of iterations for gradient descent to approximate the least squares matrix $\Phi$, in the case where the initial hypothesis $\Theta_1 = ... = \Theta_L = I$ has excess loss bounded by a small enough constant. On the other hand, we show that gradient descent fails to converge for $\Phi$ whose distance from the identity is a larger constant, and we show that some forms of regularization toward the identity in each layer do not help. If $\Phi$ is symmetric positive definite, we show that an algorithm that initializes $\Theta_i = I$ learns an $\epsilon$-approximation of $f$ using a number of updates polynomial in $L$, the condition number of $\Phi$, and $\log(d/\epsilon)$. In contrast, we show that if the least squares matrix $\Phi$ is symmetric and has a negative eigenvalue, then all members of a class of algorithms that perform gradient descent with identity initialization, and optionally regularize toward the identity in each layer, fail to converge. We analyze an algorithm for the case that $\Phi$ satisfies $u^{\top} \Phi u > 0$ for all $u$, but may not be symmetric. This algorithm uses two regularizers: one that maintains the invariant $u^{\top} \Theta_L \Theta_{L-1} ... \Theta_1 u > 0$ for all $u$, and another that "balances" $\Theta_1, ..., \Theta_L$ so that they have the same singular values.
Online Learning of Combinatorial Objects via Extended Formulation
Oct 30, 2017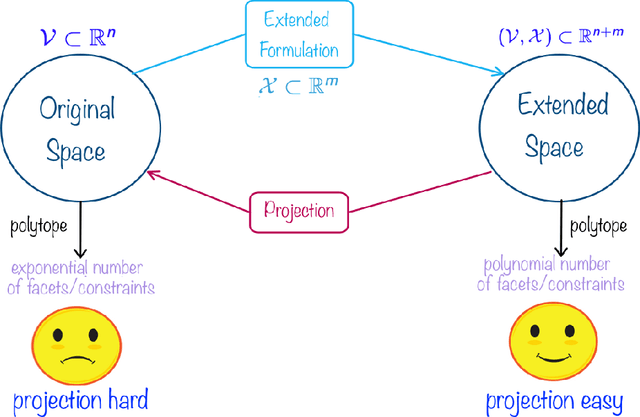
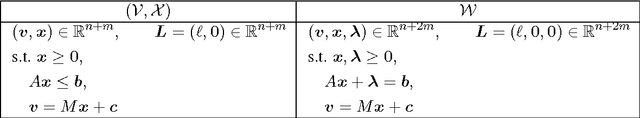
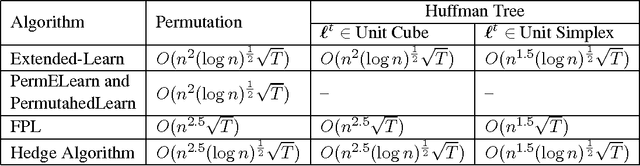
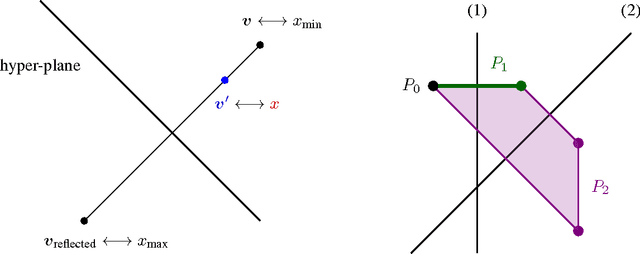
The standard techniques for online learning of combinatorial objects perform multiplicative updates followed by projections into the convex hull of all the objects. However, this methodology can be expensive if the convex hull contains many facets. For example, the convex hull of $n$-symbol Huffman trees is known to have exponentially many facets (Maurras et al., 2010). We get around this difficulty by exploiting extended formulations (Kaibel, 2011), which encode the polytope of combinatorial objects in a higher dimensional "extended" space with only polynomially many facets. We develop a general framework for converting extended formulations into efficient online algorithms with good relative loss bounds. We present applications of our framework to online learning of Huffman trees and permutations. The regret bounds of the resulting algorithms are within a factor of $O(\sqrt{\log(n)})$ of the state-of-the-art specialized algorithms for permutations, and depending on the loss regimes, improve on or match the state-of-the-art for Huffman trees. Our method is general and can be applied to other combinatorial objects.
Surprising properties of dropout in deep networks
Apr 19, 2017
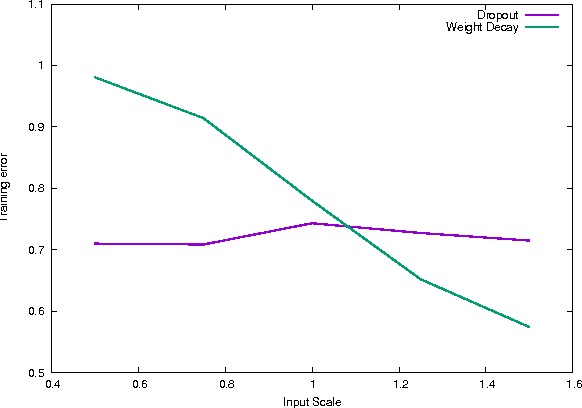
We analyze dropout in deep networks with rectified linear units and the quadratic loss. Our results expose surprising differences between the behavior of dropout and more traditional regularizers like weight decay. For example, on some simple data sets dropout training produces negative weights even though the output is the sum of the inputs. This provides a counterpoint to the suggestion that dropout discourages co-adaptation of weights. We also show that the dropout penalty can grow exponentially in the depth of the network while the weight-decay penalty remains essentially linear, and that dropout is insensitive to various re-scalings of the input features, outputs, and network weights. This last insensitivity implies that there are no isolated local minima of the dropout training criterion. Our work uncovers new properties of dropout, extends our understanding of why dropout succeeds, and lays the foundation for further progress.
On the Inductive Bias of Dropout
Feb 17, 2015

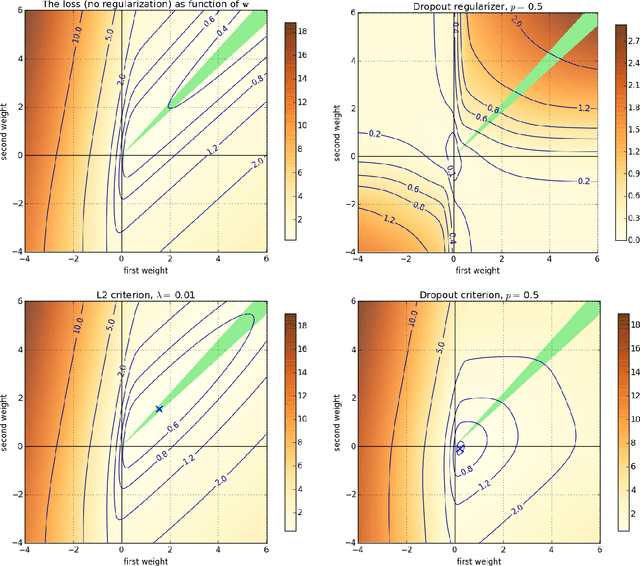

Dropout is a simple but effective technique for learning in neural networks and other settings. A sound theoretical understanding of dropout is needed to determine when dropout should be applied and how to use it most effectively. In this paper we continue the exploration of dropout as a regularizer pioneered by Wager, et.al. We focus on linear classification where a convex proxy to the misclassification loss (i.e. the logistic loss used in logistic regression) is minimized. We show: (a) when the dropout-regularized criterion has a unique minimizer, (b) when the dropout-regularization penalty goes to infinity with the weights, and when it remains bounded, (c) that the dropout regularization can be non-monotonic as individual weights increase from 0, and (d) that the dropout regularization penalty may not be convex. This last point is particularly surprising because the combination of dropout regularization with any convex loss proxy is always a convex function. In order to contrast dropout regularization with $L_2$ regularization, we formalize the notion of when different sources are more compatible with different regularizers. We then exhibit distributions that are provably more compatible with dropout regularization than $L_2$ regularization, and vice versa. These sources provide additional insight into how the inductive biases of dropout and $L_2$ regularization differ. We provide some similar results for $L_1$ regularization.
On the Necessity of Irrelevant Variables
Jun 08, 2012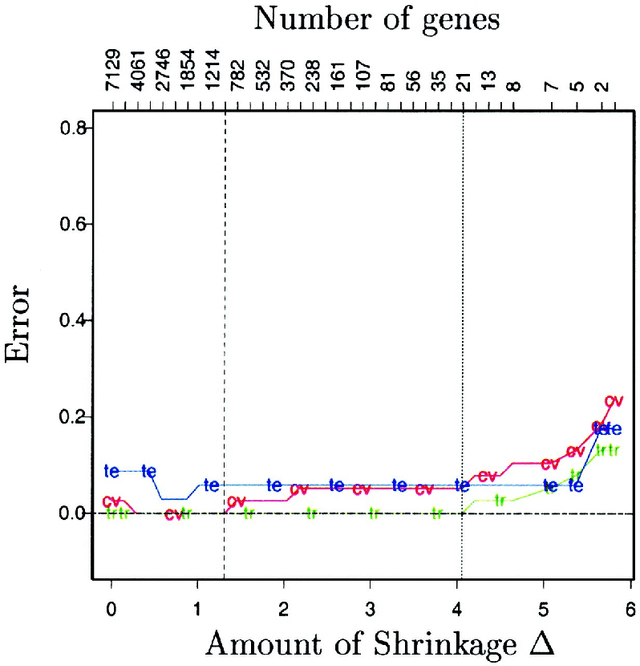


This work explores the effects of relevant and irrelevant boolean variables on the accuracy of classifiers. The analysis uses the assumption that the variables are conditionally independent given the class, and focuses on a natural family of learning algorithms for such sources when the relevant variables have a small advantage over random guessing. The main result is that algorithms relying predominately on irrelevant variables have error probabilities that quickly go to 0 in situations where algorithms that limit the use of irrelevant variables have errors bounded below by a positive constant. We also show that accurate learning is possible even when there are so few examples that one cannot determine with high confidence whether or not any individual variable is relevant.