 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 14ns-Latency 9Gb/s 0.44mm$^2$ 62pJ/b Short-Blocklength LDPC Decoder ASIC in 22FDX
Dec 19, 2025Ultra-reliable low latency communication (URLLC) is a key part of 5G wireless systems. Achieving low latency necessitates codes with short blocklengths for which polar codes with successive cancellation list (SCL) decoding typically outperform message-passing (MP)-based decoding of low-density parity-check (LDPC) codes. However, SCL decoders are known to exhibit high latency and poor area efficiency. In this paper, we propose a new short-blocklength multi-rate binary LDPC code that outperforms the 5G-LDPC code for the same blocklength and is suitable for URLLC applications using fully parallel MP. To demonstrate our code's efficacy, we present a 0.44mm$^2$ GlobalFoundries 22FDX LDPC decoder ASIC which supports three rates and achieves the lowest-in-class decoding latency of 14ns while reaching an information throughput of 9Gb/s at 62pJ/b energy efficiency for a rate-1/2 code with 128-bit blocklength.
Fixed-Throughput GRAND with FIFO Scheduling
Feb 07, 2025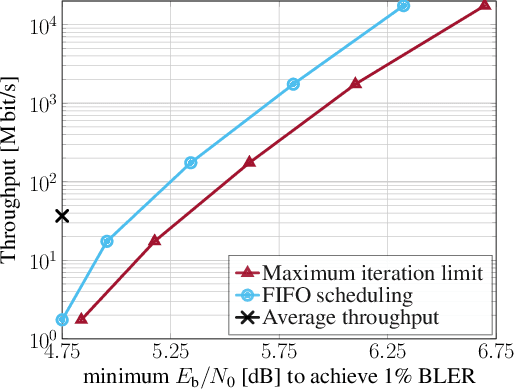
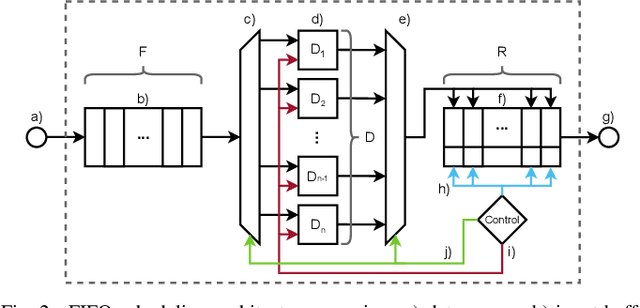
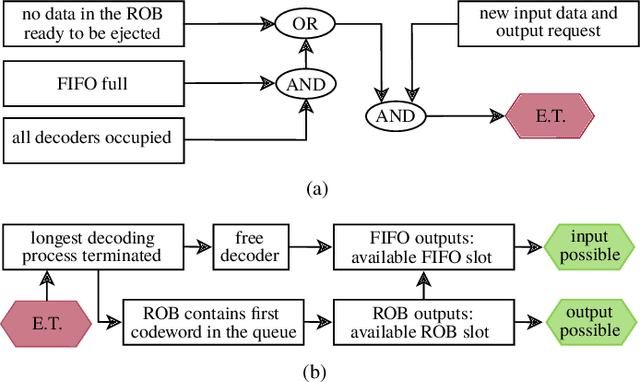
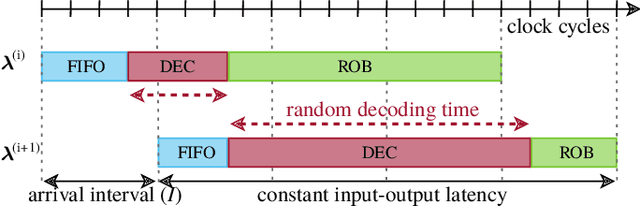
Guessing random additive noise decoding (GRAND) is a code-agnostic decoding method that iteratively guesses the noise pattern affecting the received codeword. The number of noise sequences to test depends on the noise realization. Thus, GRAND exhibits random runtime which results in nondeterministic throughput. However, real-time systems must process the incoming data at a fixed rate, necessitating a fixed-throughput decoder in order to avoid losing data. We propose a first-in first-out (FIFO) scheduling architecture that enables a fixed throughput while improving the block error rate (BLER) compared to the common approach of imposing a maximum runtime constraint per received codeword. Moreover, we demonstrate that the average throughput metric of GRAND-based hardware implementations typically provided in the literature can be misleading as one needs to operate at approximately one order of magnitude lower throughput to achieve the BLER of an unconstrained decoder.
Optimizing Puncturing Patterns of 5G NR LDPC Codes for Few-Iteration Decoding
Oct 28, 2024



Rate-matching of low-density parity-check (LDPC) codes enables a single code description to support a wide range of code lengths and rates. In 5G NR, rate matching is accomplished by extending (lifting) a base code to a desired target length and by puncturing (not transmitting) certain code bits. LDPC codes and rate matching are typically designed for the asymptotic performance limit with an ideal decoder. Practical LDPC decoders, however, carry out tens or fewer message-passing decoding iterations to achieve the target throughput and latency of modern wireless systems. We show that one can optimize LDPC code puncturing patterns for such few-iteration-constrained decoders using a method we call swapping of punctured and transmitted blocks (SPAT). Our simulation results show that SPAT yields from 0.20 dB up to 0.55 dB improved signal-to-noise ratio performance compared to the standard 5G NR LDPC code puncturing pattern for a wide range of code lengths and rates.
A 1.2 mm$^2$ 416 mW 1.44 Mmat/s 64$\times$16 Matrix Preprocessing ASIC for Massive MIMO in 22FDX
Oct 17, 2024Massive multiuser (MU) multiple-input multiple-output (MIMO) enables concurrent transmission of multiple users to a multi-antenna basestation (BS). To detect the users' data using linear equalization, the BS must perform preprocessing, which requires, among other tasks, the inversion of a matrix whose dimension equals the number of user data streams. Explicit inversion of large matrices is notoriously difficult to implement due to high complexity, stringent data dependencies that lead to high latency, and high numerical precision requirements. We propose a novel preprocessing architecture based on the block-LDL matrix factorization, which improves parallelism and, hence, reduces latency. We demonstrate the effectiveness of our architecture through (i) massive MU-MIMO system simulations with mmWave channel vectors and (ii) measurements of a 22FDX ASIC, which is, to our knowledge, the first fabricated preprocessing engine for massive MU-MIMO with 64 BS antennas and 16 single-antenna users. Our ASIC reaches a clock frequency of 870 MHz while consuming 416 mW. At its peak throughput, the ASIC preprocesses 1.44 M 64$\times$16 matrices per second at a latency of only 0.7 $\mu$s.