 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency of Feature Attribution in Deep Learning Architectures for Multi-Omics
Jul 30, 2025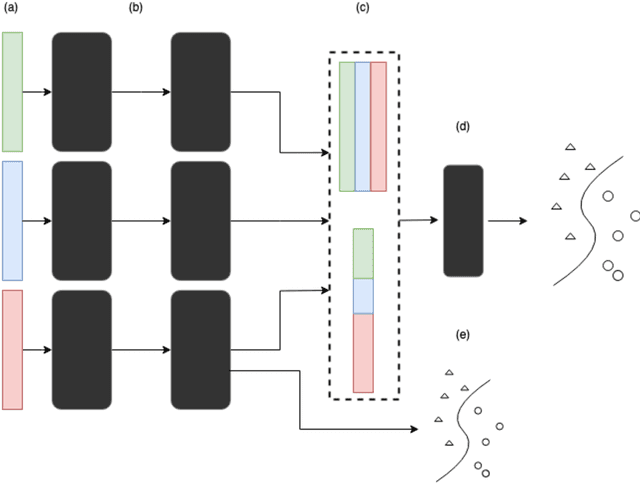
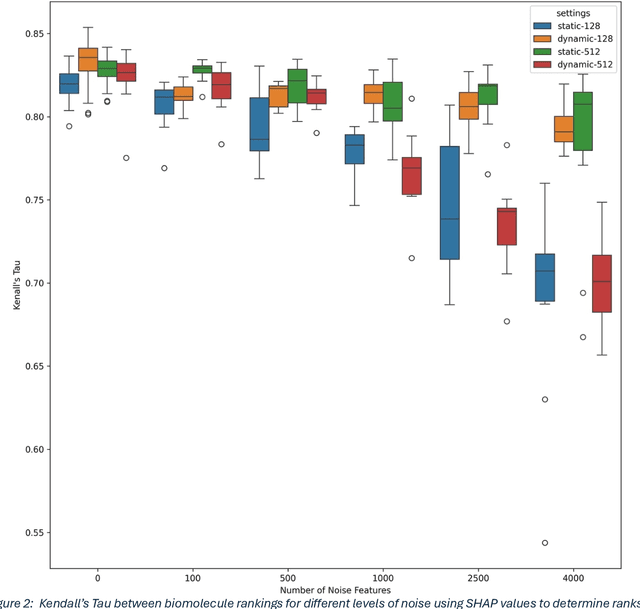
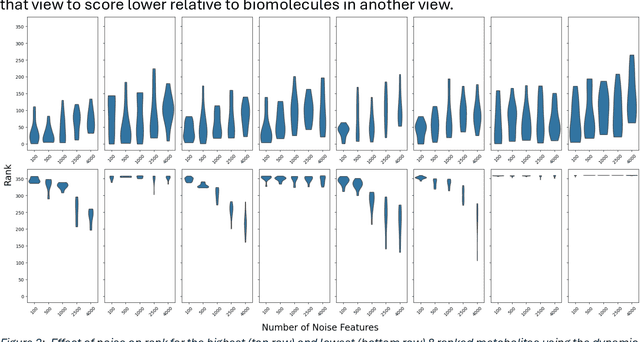
Machine and deep learning have grown in popularity and use in biological research over the last decade but still present challenges in interpretability of the fitted model. The development and use of metrics to determine features driving predictions and increase model interpretability continues to be an open area of research. We investigate the use of Shapley Additive Explanations (SHAP) on a multi-view deep learning model applied to multi-omics data for the purposes of identifying biomolecules of interest. Rankings of features via these attribution methods are compared across various architectures to evaluate consistency of the method. We perform multiple computational experiments to assess the robustness of SHAP and investigate modeling approaches and diagnostics to increase and measure the reliability of the identification of important features. Accuracy of a random-forest model fit on subsets of features selected as being most influential as well as clustering quality using only these features are used as a measure of effectiveness of the attribution method. Our findings indicate that the rankings of features resulting from SHAP are sensitive to the choice of architecture as well as different random initializations of weights, suggesting caution when using attribution methods on multi-view deep learning models applied to multi-omics data. We present an alternative, simple method to assess the robustness of identification of important biomolecules.
On the Behavior of Audio-Visual Fusion Architectures in Identity Verification Tasks
Nov 09, 2023



We train an identity verification architecture and evaluate modifications to the part of the model that combines audio and visual representations, including in scenarios where one input is missing in either of two examples to be compared. We report results on the Voxceleb1-E test set that suggest averaging the output embeddings improves error rate in the full-modality setting and when a single modality is missing, and makes more complete use of the embedding space than systems which use shared layers and discuss possible reasons for this behavior.