 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed LSTM-Learning from Differentially Private Label Proportions
Jan 15, 2023


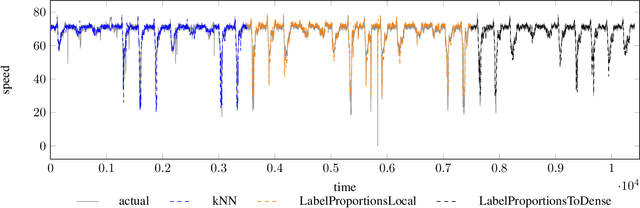
Data privacy and decentralised data collection has become more and more popular in recent years. In order to solve issues with privacy, communication bandwidth and learning from spatio-temporal data, we will propose two efficient models which use Differential Privacy and decentralized LSTM-Learning: One, in which a Long Short Term Memory (LSTM) model is learned for extracting local temporal node constraints and feeding them into a Dense-Layer (LabelProportionToLocal). The other approach extends the first one by fetching histogram data from the neighbors and joining the information with the LSTM output (LabelProportionToDense). For evaluation two popular datasets are used: Pems-Bay and METR-LA. Additionally, we provide an own dataset, which is based on LuST. The evaluation will show the tradeoff between performance and data privacy.
LOSDD: Leave-Out Support Vector Data Description for Outlier Detection
Dec 27, 2022



Support Vector Machines have been successfully used for one-class classification (OCSVM, SVDD) when trained on clean data, but they work much worse on dirty data: outliers present in the training data tend to become support vectors, and are hence considered "normal". In this article, we improve the effectiveness to detect outliers in dirty training data with a leave-out strategy: by temporarily omitting one candidate at a time, this point can be judged using the remaining data only. We show that this is more effective at scoring the outlierness of points than using the slack term of existing SVM-based approaches. Identified outliers can then be removed from the data, such that outliers hidden by other outliers can be identified, to reduce the problem of masking. Naively, this approach would require training N individual SVMs (and training $O(N^2)$ SVMs when iteratively removing the worst outliers one at a time), which is prohibitively expensive. We will discuss that only support vectors need to be considered in each step and that by reusing SVM parameters and weights, this incremental retraining can be accelerated substantially. By removing candidates in batches, we can further improve the processing time, although it obviously remains more costly than training a single SVM.