 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrend Extrapolation for Technology Forecasting: Leveraging LSTM Neural Networks for Trend Analysis of Space Exploration Vessels
Dec 17, 2025Forecasting technological advancement in complex domains such as space exploration presents significant challenges due to the intricate interaction of technical, economic, and policy-related factors. The field of technology forecasting has long relied on quantitative trend extrapolation techniques, such as growth curves (e.g., Moore's law) and time series models, to project technological progress. To assess the current state of these methods, we conducted an updated systematic literature review (SLR) that incorporates recent advances. This review highlights a growing trend toward machine learning-based hybrid models. Motivated by this review, we developed a forecasting model that combines long short-term memory (LSTM) neural networks with an augmentation of Moore's law to predict spacecraft lifetimes. Operational lifetime is an important engineering characteristic of spacecraft and a potential proxy for technological progress in space exploration. Lifetimes were modeled as depending on launch date and additional predictors. Our modeling analysis introduces a novel advance in the recently introduced Start Time End Time Integration (STETI) approach. STETI addresses a critical right censoring problem known to bias lifetime analyses: the more recent the launch dates, the shorter the lifetimes of the spacecraft that have failed and can thus contribute lifetime data. Longer-lived spacecraft are still operating and therefore do not contribute data. This systematically distorts putative lifetime versus launch date curves by biasing lifetime estimates for recent launch dates downward. STETI mitigates this distortion by interconverting between expressing lifetimes as functions of launch time and modeling them as functions of failure time. The results provide insights relevant to space mission planning and policy decision-making.
Quantitative Technology Forecasting: a Review of Trend Extrapolation Methods
Jan 04, 2024Quantitative technology forecasting uses quantitative methods to understand and project technological changes. It is a broad field encompassing many different techniques and has been applied to a vast range of technologies. A widely used approach in this field is trend extrapolation. Based on the publications available to us, there has been little or no attempt made to systematically review the empirical evidence on quantitative trend extrapolation techniques. This study attempts to close this gap by conducting a systematic review of technology forecasting literature addressing the application of quantitative trend extrapolation techniques. We identified 25 studies relevant to the objective of this research and classified the techniques used in the studies into different categories, among which growth curves and time series methods were shown to remain popular over the past decade, while newer methods, such as machine learning-based hybrid models, have emerged in recent years. As more effort and evidence are needed to determine if hybrid models are superior to traditional methods, we expect to see a growing trend in the development and application of hybrid models to technology forecasting.
ASI: Accuracy-Stability Index for Evaluating Deep Learning Models
Nov 26, 2023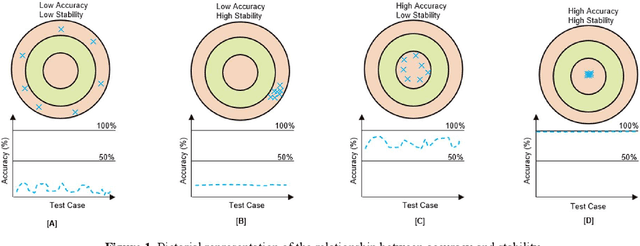
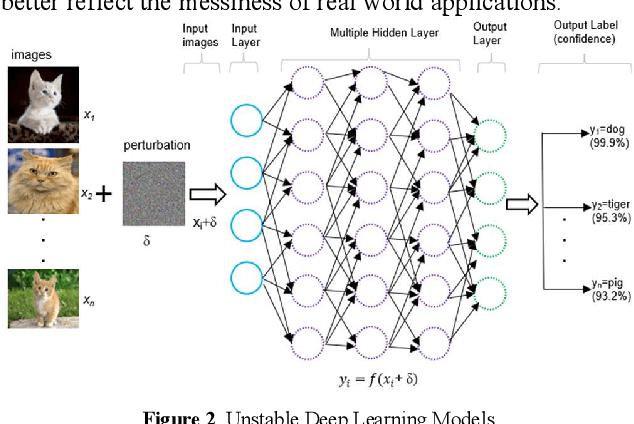
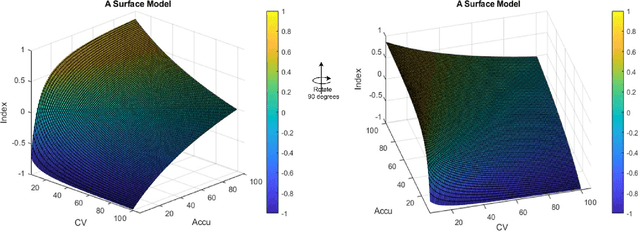
In the context of deep learning research, where model introductions continually occur, the need for effective and efficient evaluation remains paramount. Existing methods often emphasize accuracy metrics, overlooking stability. To address this, the paper introduces the Accuracy-Stability Index (ASI), a quantitative measure incorporating both accuracy and stability for assessing deep learning models. Experimental results demonstrate the application of ASI, and a 3D surface model is presented for visualizing ASI, mean accuracy, and coefficient of variation. This paper addresses the important issue of quantitative benchmarking metrics for deep learning models, providing a new approach for accurately evaluating accuracy and stability of deep learning models. The paper concludes with discussions on potential weaknesses and outlines future research directions.
Automating Systematic Literature Reviews with Natural Language Processing and Text Mining: a Systematic Literature Review
Nov 20, 2022

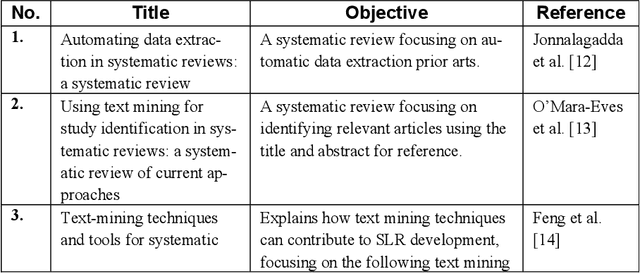

Objectives: An SLR is presented focusing on text mining based automation of SLR creation. The present review identifies the objectives of the automation studies and the aspects of those steps that were automated. In so doing, the various ML techniques used, challenges, limitations and scope of further research are explained. Methods: Accessible published literature studies that primarily focus on automation of study selection, study quality assessment, data extraction and data synthesis portions of SLR. Twenty-nine studies were analyzed. Results: This review identifies the objectives of the automation studies, steps within the study selection, study quality assessment, data extraction and data synthesis portions that were automated, the various ML techniques used, challenges, limitations and scope of further research. Discussion: We describe uses of NLP/TM techniques to support increased automation of systematic literature reviews. This area has attracted increase attention in the last decade due to significant gaps in the applicability of TM to automate steps in the SLR process. There are significant gaps in the application of TM and related automation techniques in the areas of data extraction, monitoring, quality assessment and data synthesis. There is thus a need for continued progress in this area, and this is expected to ultimately significantly facilitate the construction of systematic literature reviews.
Discovering Limitations of Image Quality Assessments with Noised Deep Learning Image Sets
Oct 19, 2022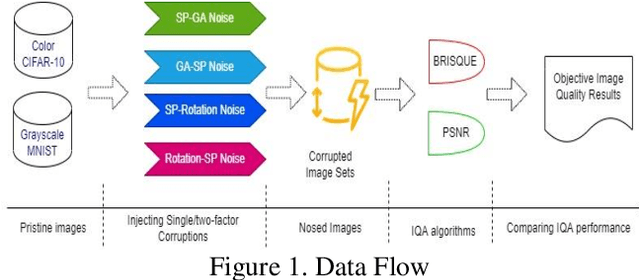
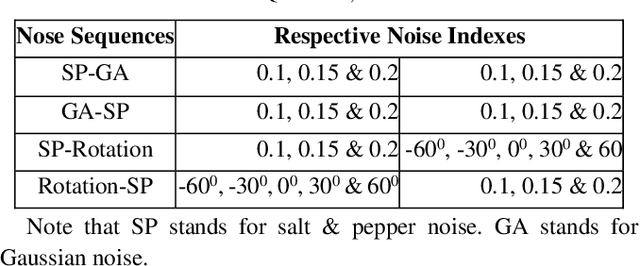

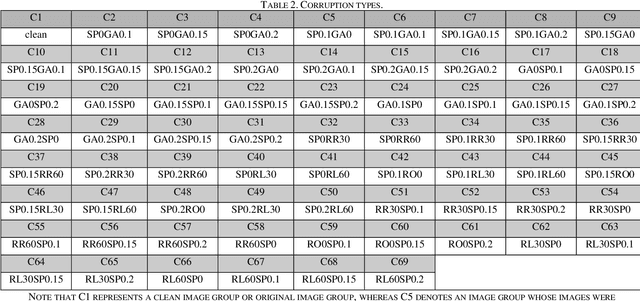
Image quality is important, and it can affect overall performance in image processing and computer vision as well as for numerous other reasons. Image quality assessment (IQA) is consequently a vital task in different applications from aerial photography interpretation to object detection to medical image analysis. In previous research, the BRISQUE algorithm and the PSNR algorithm were evaluated with high resolution ( 512*384 pixels per image), but relatively small image sets (4,744 images). However, scientists have not evaluated IQA algorithms on low resolution (32*32 pixels per image), multi-perturbation, big image sets (for example, 60,000 different images not counting their perturbations). This study explores these two IQA algorithms through experimental investigation. We first chose two deep learning image sets, CIFAR-10 and MNIST. Then, we added 68 perturbations that add noise to the images in specific sequences and noise intensities. In addition, we tracked the performance outputs of the two IQA algorithms with singly and multiply noised images. After quantitatively analyzing experimental results, we report the limitations of the two IQAs with these noised CIFAR-10 and MNIST image sets. We also explain three potential root causes for performance degradation. These findings point out weaknesses of the two IQA algorithms. The research results provide guidance to scientists and engineers developing accurate, robust IQA algorithms. In addition to supporting future scientific research and industrial projects, all source codes are shared on the website: https://github.com/caperock/imagequality
Recent, rapid advancement in visual question answering architecture: a review
Mar 31, 2022
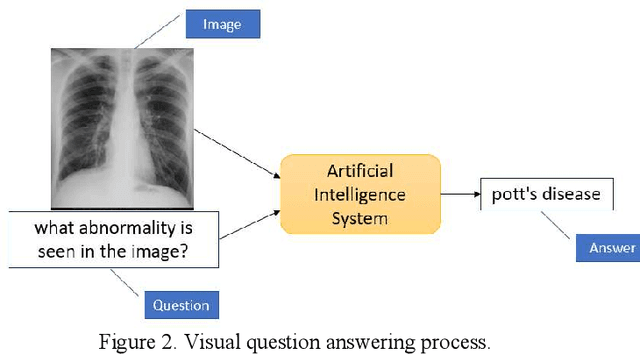
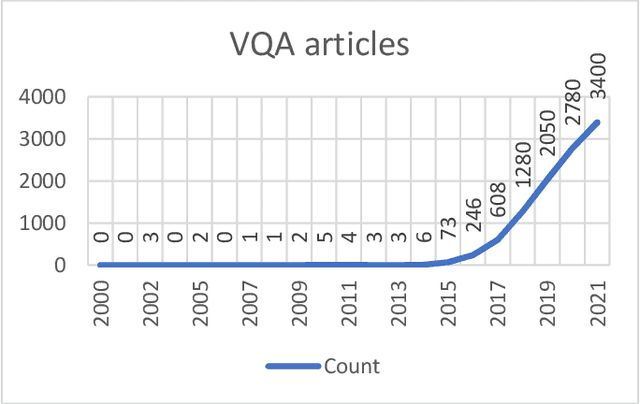
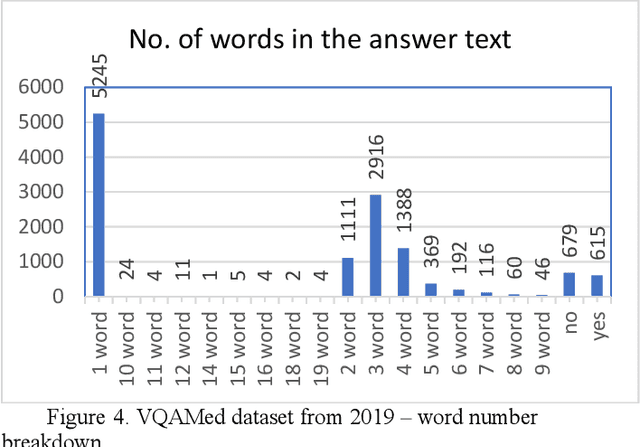
Understanding visual question answering is going to be crucial for numerous human activities. However, it presents major challenges at the heart of the artificial intelligence endeavor. This paper presents an update on the rapid advancements in visual question answering using images that have occurred in the last couple of years. Tremendous growth in research on improving visual question answering system architecture has been published recently, showing the importance of multimodal architectures. Several points on the benefits of visual question answering are mentioned in the review paper by Manmadhan et al. (2020), on which the present article builds, including subsequent updates in the field.
Benchmarking Robustness of Deep Learning Classifiers Using Two-Factor Perturbation
Mar 02, 2022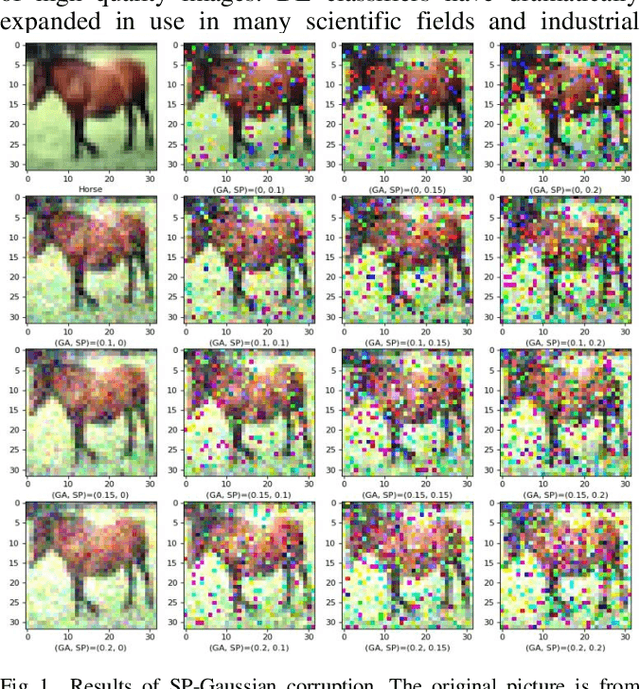

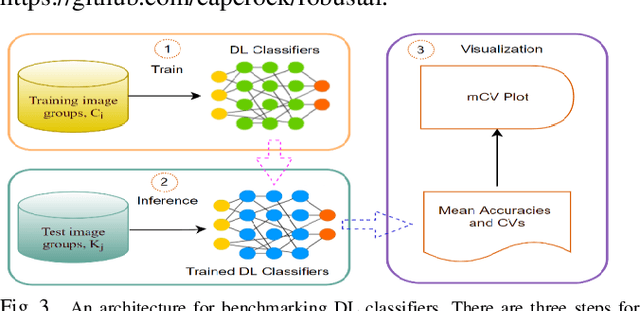
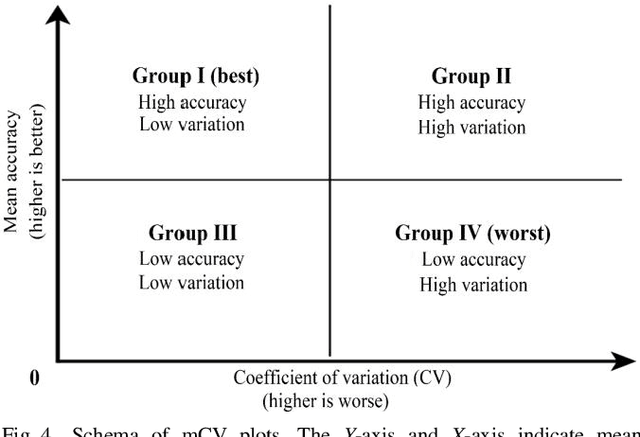
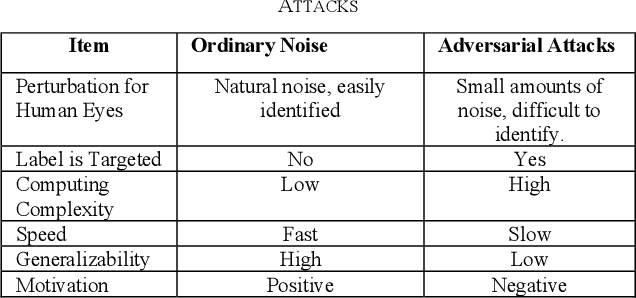
Accuracies of deep learning (DL) classifiers are often unstable in that they may change significantly when retested on adversarial images, imperfect images, or perturbed images. This paper adds to the fundamental body of work on benchmarking the robustness of DL classifiers on defective images. To measure robust DL classifiers, previous research reported on single-factor corruption. We created comprehensive 69 benchmarking image sets, including a clean set, sets with single factor perturbations, and sets with two-factor perturbation conditions. The state-of-the-art two-factor perturbation includes (a) two digital perturbations (salt & pepper noise and Gaussian noise) applied in both sequences, and (b) one digital perturbation (salt & pepper noise) and a geometric perturbation (rotation) applied in both sequences. Previous research evaluating DL classifiers has often used top-1/top-5 accuracy. We innovate a new two-dimensional, statistical matrix to evaluating robustness of DL classifiers. Also, we introduce a new visualization tool, including minimum accuracy, maximum accuracy, mean accuracies, and coefficient of variation (CV), for benchmarking robustness of DL classifiers. Comparing with single factor corruption, we first report that using two-factor perturbed images improves both robustness and accuracy of DL classifiers. All source codes and related image sets are shared on the Website at http://cslinux.semo.edu/david/data to support future academic research and industry projects.
Benchmarking Deep Learning Classifiers: Beyond Accuracy
Mar 02, 2021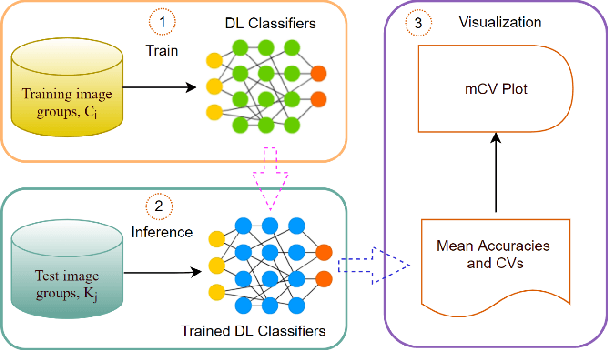

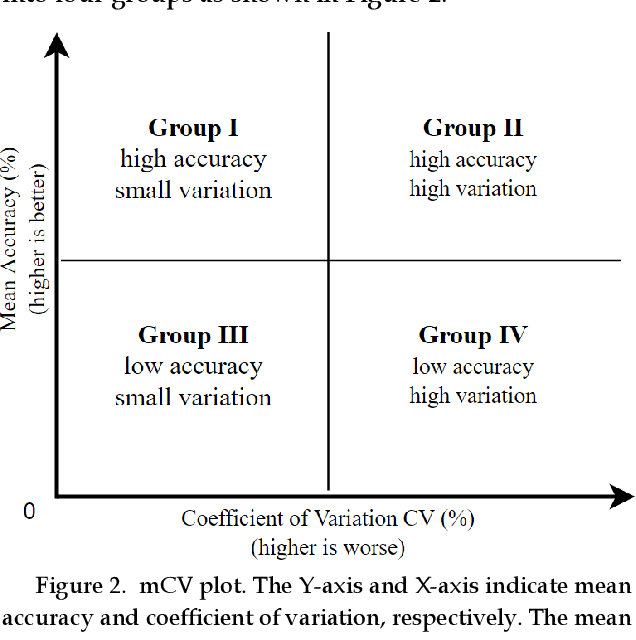
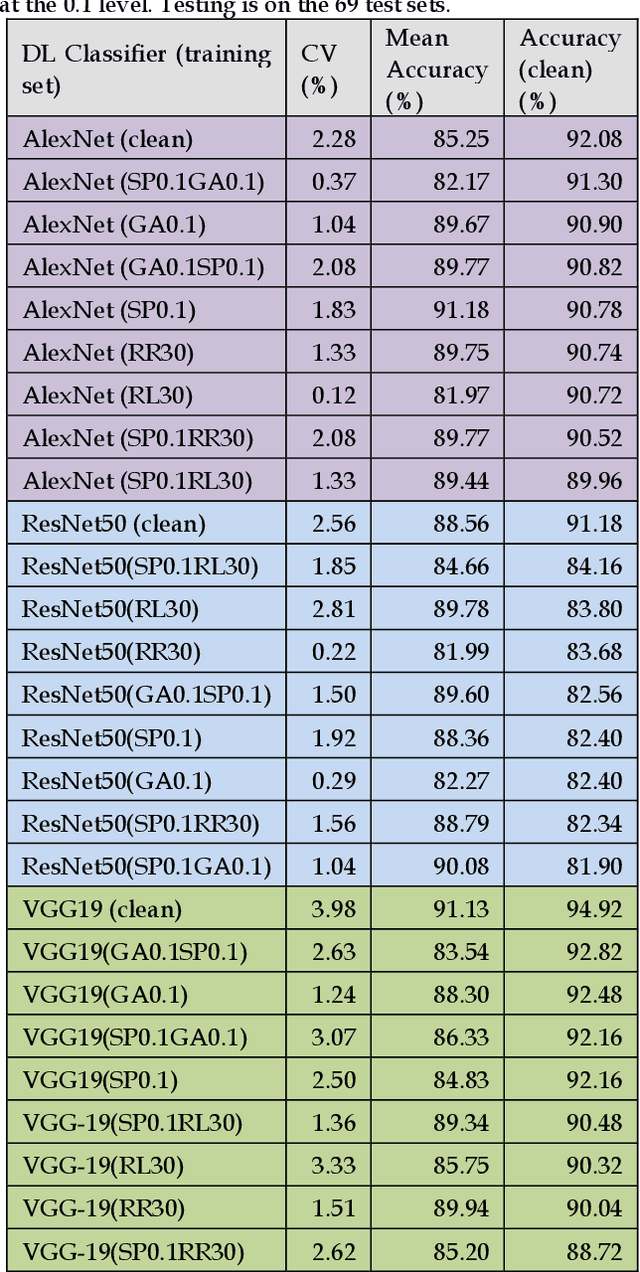
Previous research evaluating deep learning (DL) classifiers has often used top-1/top-5 accuracy. However, the accuracy of DL classifiers is unstable in that it often changes significantly when retested on imperfect or adversarial images. This paper adds to the small but fundamental body of work on benchmarking the robustness of DL classifiers on imperfect images by proposing a two-dimensional metric, consisting of mean accuracy and coefficient of variation, to measure the robustness of DL classifiers. Spearman's rank correlation coefficient and Pearson's correlation coefficient are used and their independence evaluated. A statistical plot we call mCV is presented which aims to help visualize the robustness of the performance of DL classifiers across varying amounts of imperfection in tested images. Finally, we demonstrate that defective images corrupted by two-factor corruption could be used to improve the robustness of DL classifiers. All source codes and related image sets are shared on a website (http://www.animpala.com) to support future research projects.
Benchmarking Deep Learning Hardware and Frameworks: Qualitative Metrics
Jul 09, 2019
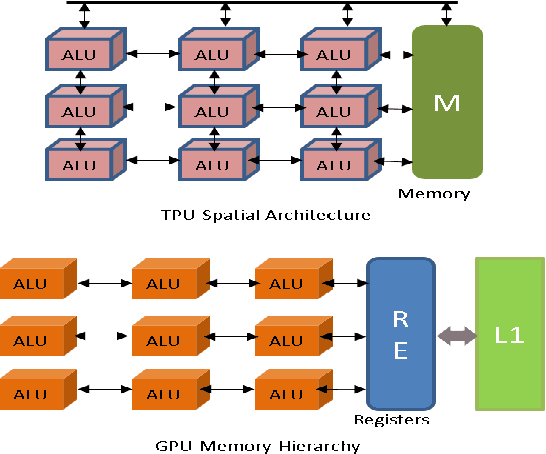
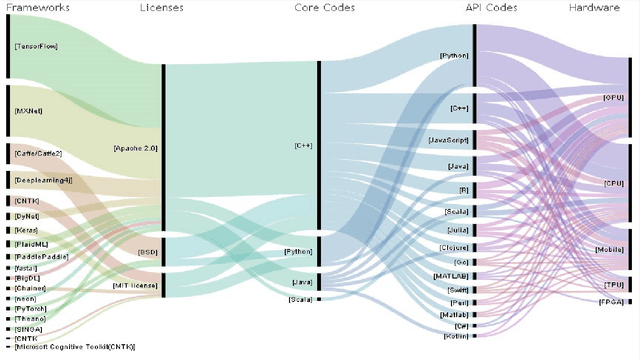
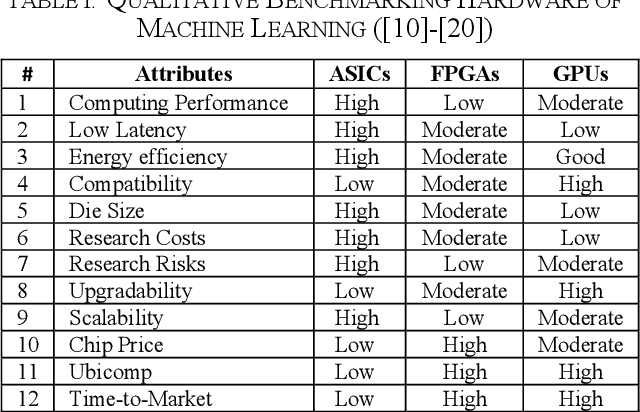
Previous survey papers offer knowledge of deep learning hardware devices and software frameworks. This paper introduces benchmarking principles, surveys machine learning devices including GPUs, FPGAs, and ASICs, and reviews deep learning software frameworks. It also reviews these technologies with respect to benchmarking from the angles of our 7-metric approach to frameworks and 12-metric approach to hardware platforms. After reading the paper, the audience will understand seven benchmarking principles, generally know that differential characteristics of mainstream AI devices, qualitatively compare deep learning hardware through our 12-metric approach for benchmarking hardware, and read benchmarking results of 16 deep learning frameworks via our 7-metric set for benchmarking frameworks.