 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Space of Adversarial Perturbations against Image Filters
Mar 05, 2020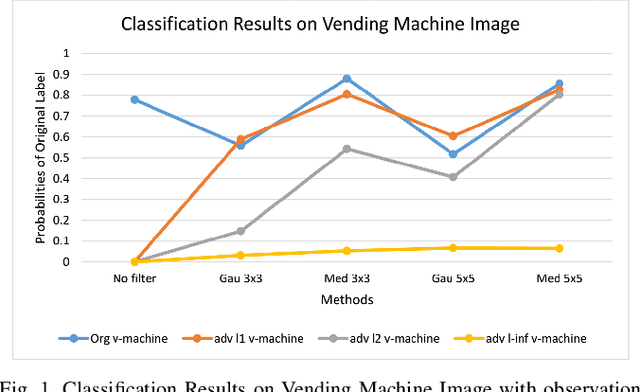
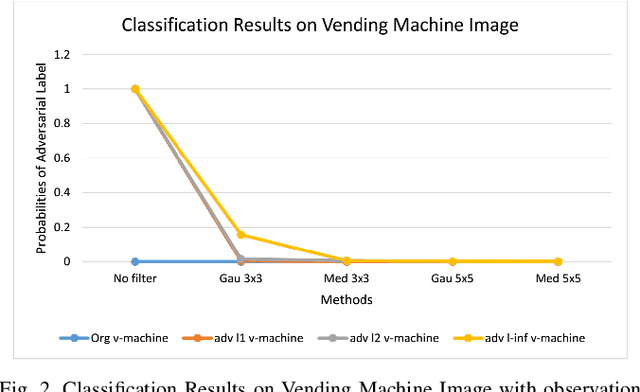
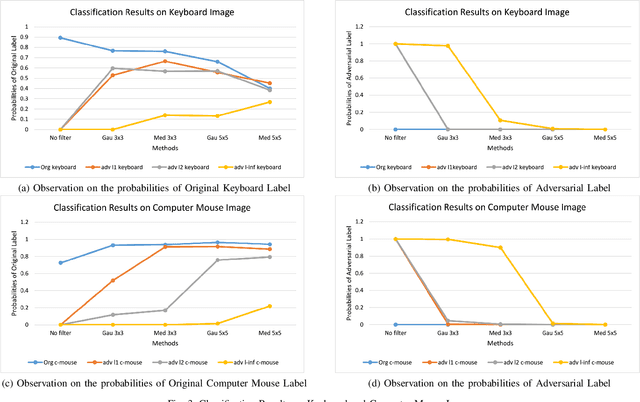
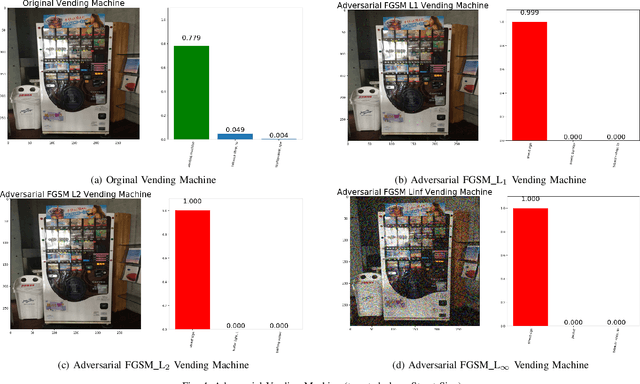
The superiority of deep learning performance is threatened by safety issues for itself. Recent findings have shown that deep learning systems are very weak to adversarial examples, an attack form that was altered by the attacker's intent to deceive the deep learning system. There are many proposed defensive methods to protect deep learning systems against adversarial examples. However, there is still a lack of principal strategies to deceive those defensive methods. Any time a particular countermeasure is proposed, a new powerful adversarial attack will be invented to deceive that countermeasure. In this study, we focus on investigating the ability to create adversarial patterns in search space against defensive methods that use image filters. Experimental results conducted on the ImageNet dataset with image classification tasks showed the correlation between the search space of adversarial perturbation and filters. These findings open a new direction for building stronger offensive methods towards deep learning systems.
Automated Detection System for Adversarial Examples with High-Frequency Noises Sieve
Aug 05, 2019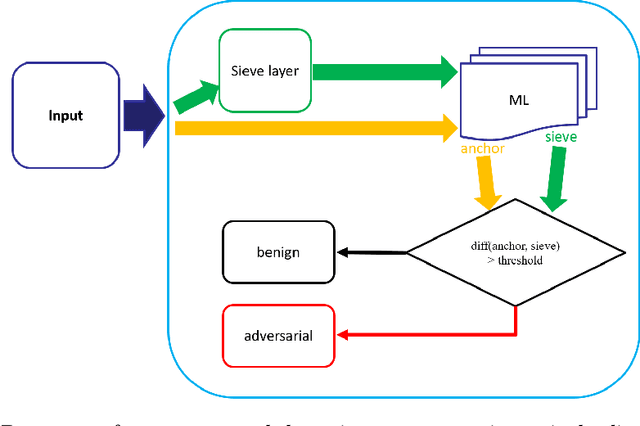
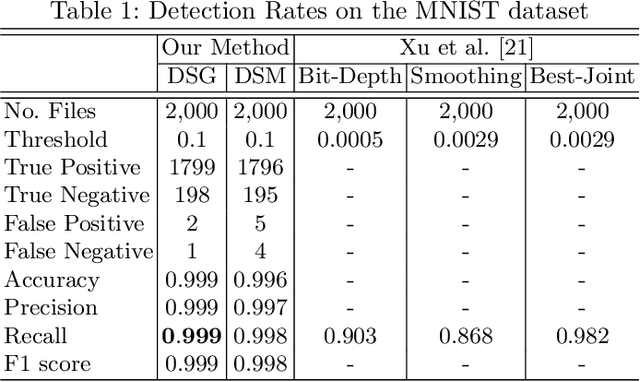

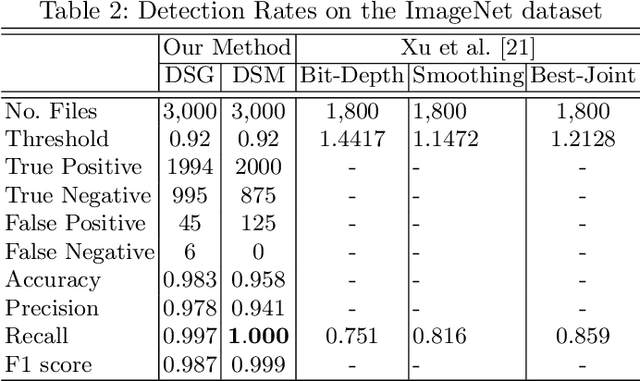
Deep neural networks are being applied in many tasks with encouraging results, and have often reached human-level performance. However, deep neural networks are vulnerable to well-designed input samples called adversarial examples. In particular, neural networks tend to misclassify adversarial examples that are imperceptible to humans. This paper introduces a new detection system that automatically detects adversarial examples on deep neural networks. Our proposed system can mostly distinguish adversarial samples and benign images in an end-to-end manner without human intervention. We exploit the important role of the frequency domain in adversarial samples and propose a method that detects malicious samples in observations. When evaluated on two standard benchmark datasets (MNIST and ImageNet), our method achieved an out-detection rate of 99.7 - 100% in many settings.
Image Transformation can make Neural Networks more robust against Adversarial Examples
Jan 10, 2019
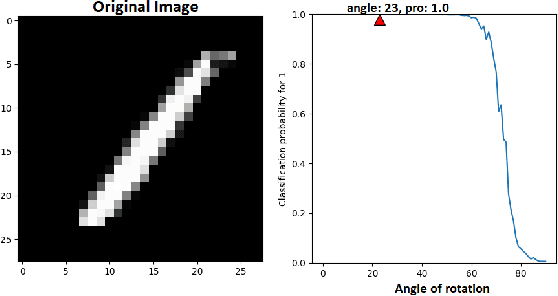
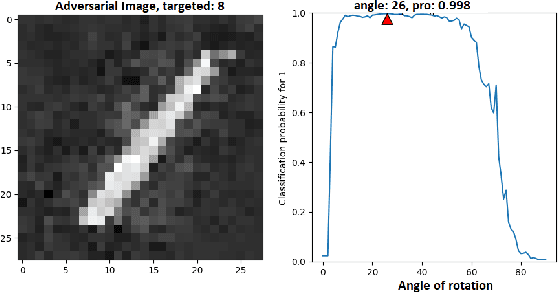
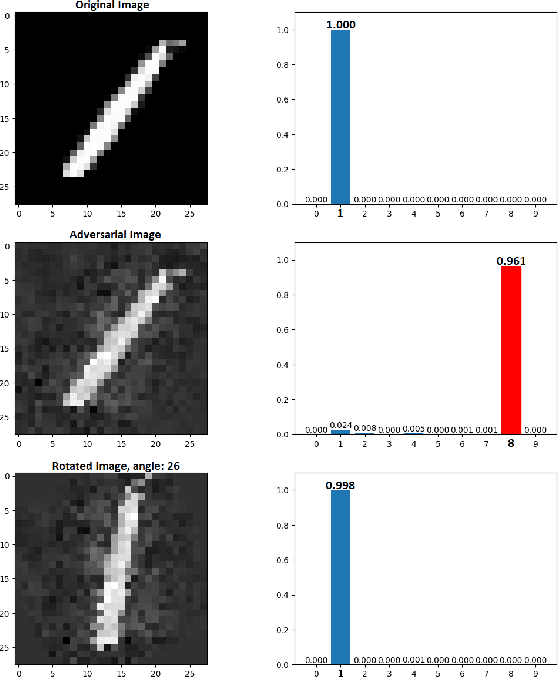
Neural networks are being applied in many tasks related to IoT with encouraging results. For example, neural networks can precisely detect human, objects and animal via surveillance camera for security purpose. However, neural networks have been recently found vulnerable to well-designed input samples that called adversarial examples. Such issue causes neural networks to misclassify adversarial examples that are imperceptible to humans. We found giving a rotation to an adversarial example image can defeat the effect of adversarial examples. Using MNIST number images as the original images, we first generated adversarial examples to neural network recognizer, which was completely fooled by the forged examples. Then we rotated the adversarial image and gave them to the recognizer to find the recognizer to regain the correct recognition. Thus, we empirically confirmed rotation to images can protect pattern recognizer based on neural networks from adversarial example attacks.