 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Interval Retrieval using Convolutional Neural Networks
Sep 21, 2021
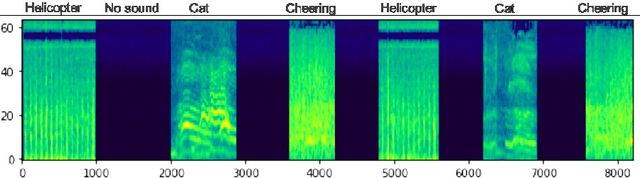
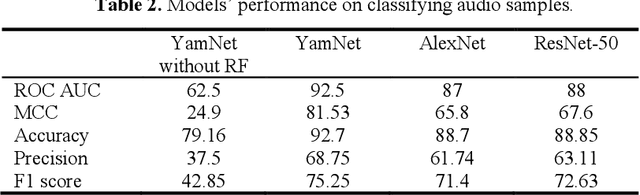
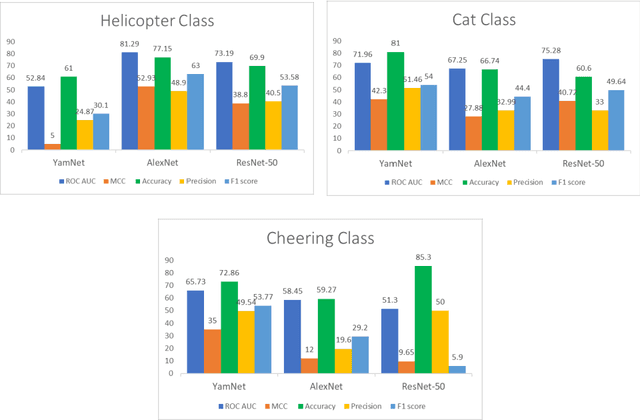
Modern streaming services are increasingly labeling videos based on their visual or audio content. This typically augments the use of technologies such as AI and ML by allowing to use natural speech for searching by keywords and video descriptions. Prior research has successfully provided a number of solutions for speech to text, in the case of a human speech, but this article aims to investigate possible solutions to retrieve sound events based on a natural language query, and estimate how effective and accurate they are. In this study, we specifically focus on the YamNet, AlexNet, and ResNet-50 pre-trained models to automatically classify audio samples using their respective melspectrograms into a number of predefined classes. The predefined classes can represent sounds associated with actions within a video fragment. Two tests are conducted to evaluate the performance of the models on two separate problems: audio classification and intervals retrieval based on a natural language query. Results show that the benchmarked models are comparable in terms of performance, with YamNet slightly outperforming the other two models. YamNet was able to classify single fixed-size audio samples with 92.7% accuracy and 68.75% precision while its average accuracy on intervals retrieval was 71.62% and precision was 41.95%. The investigated method may be embedded into an automated event marking architecture for streaming services.