 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALO-VC: Any-to-any Low-latency One-shot Voice Conversion
Jun 01, 2023



This paper presents ALO-VC, a non-parallel low-latency one-shot phonetic posteriorgrams (PPGs) based voice conversion method. ALO-VC enables any-to-any voice conversion using only one utterance from the target speaker, with only 47.5 ms future look-ahead. The proposed hybrid signal processing and machine learning pipeline combines a pre-trained speaker encoder, a pitch predictor to predict the converted speech's prosody, and positional encoding to convey the phoneme's location information. We introduce two system versions: ALO-VC-R, which uses a pre-trained d-vector speaker encoder, and ALO-VC-E, which improves performance using the ECAPA-TDNN speaker encoder. The experimental results demonstrate both ALO-VC-R and ALO-VC-E can achieve comparable performance to non-causal baseline systems on the VCTK dataset and two out-of-domain datasets. Furthermore, both proposed systems can be deployed on a single CPU core with 55 ms latency and 0.78 real-time factor. Our demo is available online.
BC-VAD: A Robust Bone Conduction Voice Activity Detection
Dec 06, 2022Voice Activity Detection (VAD) is a fundamental module in many audio applications. Recent state-of-the-art VAD systems are often based on neural networks, but they require a computational budget that usually exceeds the capabilities of a small battery-operated device when preserving the performance of larger models. In this work, we rely on the input from a bone conduction microphone (BCM) to design an efficient VAD (BC-VAD) robust against residual non-stationary noises originating from the environment or speakers not wearing the BCM.We first show that a larger VAD system (58k parameters) achieves state-of-the-art results on a publicly available benchmark but fails when running on bone conduction signals. We then compare its variant BC-VAD (5k parameters and trained on BC data) with a baseline especially designed for a BCM and show that the proposed method achieves better performances under various metrics while keeping the realtime processing requirement for a microcontroller.
AC-VC: Non-parallel Low Latency Phonetic Posteriorgrams Based Voice Conversion
Nov 12, 2021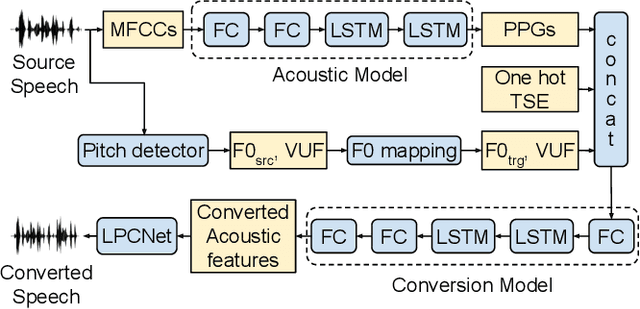
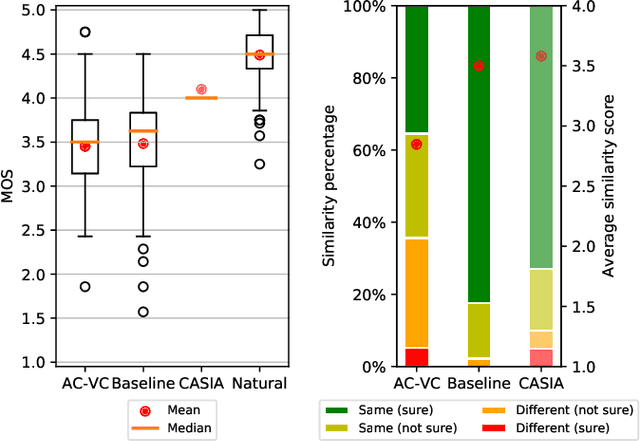
This paper presents AC-VC (Almost Causal Voice Conversion), a phonetic posteriorgrams based voice conversion system that can perform any-to-many voice conversion while having only 57.5 ms future look-ahead. The complete system is composed of three neural networks trained separately with non-parallel data. While most of the current voice conversion systems focus primarily on quality irrespective of algorithmic latency, this work elaborates on designing a method using a minimal amount of future context thus allowing a future real-time implementation. According to a subjective listening test organized in this work, the proposed AC-VC system achieves parity with the non-causal ASR-TTS baseline of the Voice Conversion Challenge 2020 in naturalness with a MOS of 3.5. In contrast, the results indicate that missing future context impacts speaker similarity. Obtained similarity percentage of 65% is lower than the similarity of current best voice conversion systems.