 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-VC: Non-parallel Low Latency Phonetic Posteriorgrams Based Voice Conversion
Paper and Code
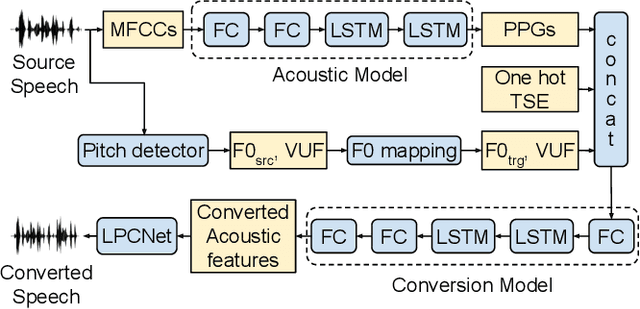
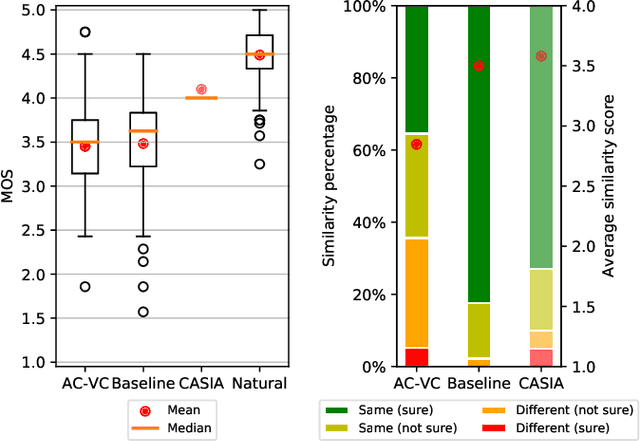
This paper presents AC-VC (Almost Causal Voice Conversion), a phonetic posteriorgrams based voice conversion system that can perform any-to-many voice conversion while having only 57.5 ms future look-ahead. The complete system is composed of three neural networks trained separately with non-parallel data. While most of the current voice conversion systems focus primarily on quality irrespective of algorithmic latency, this work elaborates on designing a method using a minimal amount of future context thus allowing a future real-time implementation. According to a subjective listening test organized in this work, the proposed AC-VC system achieves parity with the non-causal ASR-TTS baseline of the Voice Conversion Challenge 2020 in naturalness with a MOS of 3.5. In contrast, the results indicate that missing future context impacts speaker similarity. Obtained similarity percentage of 65% is lower than the similarity of current best voice conversion systems.