 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Voting: Human Choices and AI Collective Decision Making
Jan 31, 2024
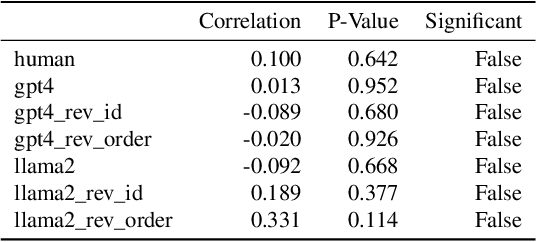
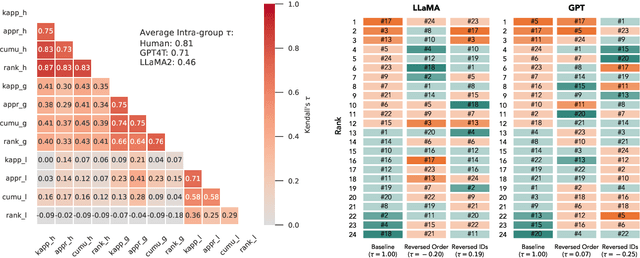
This paper investigates the voting behaviors of Large Language Models (LLMs), particularly OpenAI's GPT4 and LLaMA2, and their alignment with human voting patterns. Our approach included a human voting experiment to establish a baseline for human preferences and a parallel experiment with LLM agents. The study focused on both collective outcomes and individual preferences, revealing differences in decision-making and inherent biases between humans and LLMs. We observed a trade-off between preference diversity and alignment in LLMs, with a tendency towards more uniform choices as compared to the diverse preferences of human voters. This finding indicates that LLMs could lead to more homogenized collective outcomes when used in voting assistance, underscoring the need for cautious integration of LLMs into democratic processes.
Dynamic value alignment through preference aggregation of multiple objectives
Oct 09, 2023The development of ethical AI systems is currently geared toward setting objective functions that align with human objectives. However, finding such functions remains a research challenge, while in RL, setting rewards by hand is a fairly standard approach. We present a methodology for dynamic value alignment, where the values that are to be aligned with are dynamically changing, using a multiple-objective approach. We apply this approach to extend Deep $Q$-Learning to accommodate multiple objectives and evaluate this method on a simplified two-leg intersection controlled by a switching agent.Our approach dynamically accommodates the preferences of drivers on the system and achieves better overall performance across three metrics (speeds, stops, and waits) while integrating objectives that have competing or conflicting actions.
Deep-learned orthogonal basis patterns for fast, noise-robust single-pixel imaging
May 18, 2022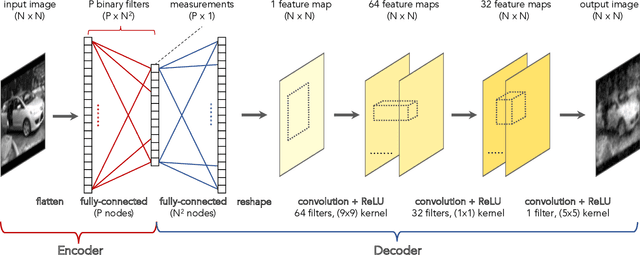

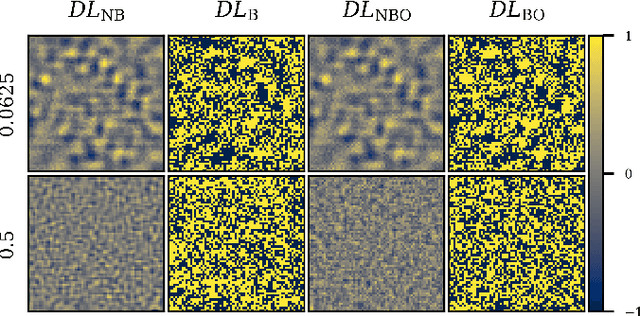
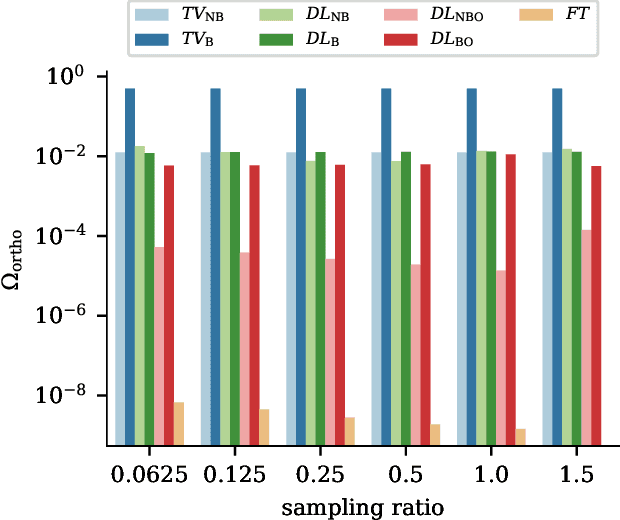
Single-pixel imaging (SPI) is a novel, unconventional method that goes beyond the notion of traditional cameras but can be computationally expensive and slow for real-time applications. Deep learning has been proposed as an alternative approach for solving the SPI reconstruction problem, but a detailed analysis of its performance and generated basis patterns when used for SPI is limited. We present a modified deep convolutional autoencoder network (DCAN) for SPI on 64x64 pixel images with up to 6.25% compression ratio and apply binary and orthogonality regularizers during training. Training a DCAN with these regularizers allows it to learn multiple measurement bases that have combinations of binary or non-binary, and orthogonal or non-orthogonal patterns. We compare the reconstruction quality, orthogonality of the patterns, and robustness to noise of the resulting DCAN models to traditional SPI reconstruction algorithms (such as Total Variation minimization and Fourier Transform). Our DCAN models can be trained to be robust to noise while still having fast enough reconstruction times (~3 ms per frame) to be viable for real-time imaging.