 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Voting: Human Choices and AI Collective Decision Making
Paper and Code

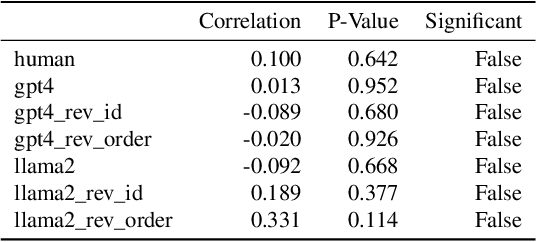
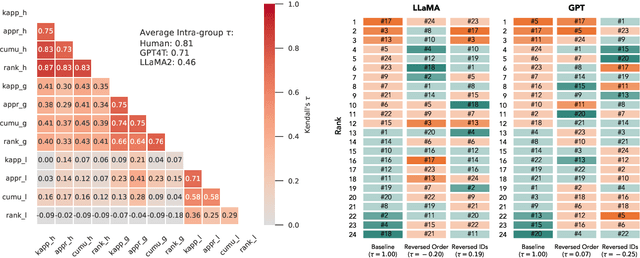
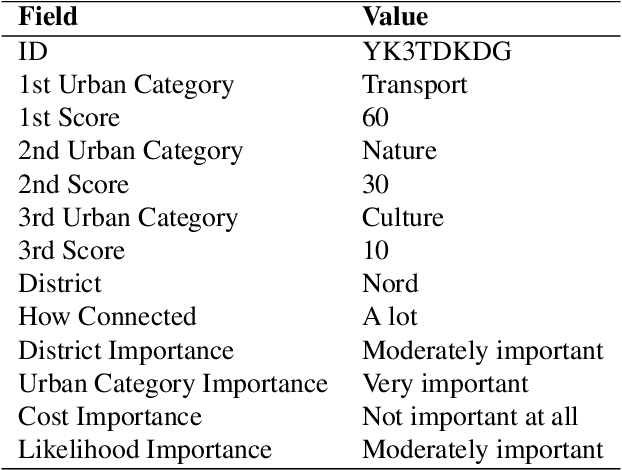
This paper investigates the voting behaviors of Large Language Models (LLMs), particularly OpenAI's GPT4 and LLaMA2, and their alignment with human voting patterns. Our approach included a human voting experiment to establish a baseline for human preferences and a parallel experiment with LLM agents. The study focused on both collective outcomes and individual preferences, revealing differences in decision-making and inherent biases between humans and LLMs. We observed a trade-off between preference diversity and alignment in LLMs, with a tendency towards more uniform choices as compared to the diverse preferences of human voters. This finding indicates that LLMs could lead to more homogenized collective outcomes when used in voting assistance, underscoring the need for cautious integration of LLMs into democratic processes.