 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Centric Evaluation of OCR Systems for Kwak'wala
Feb 26, 2023
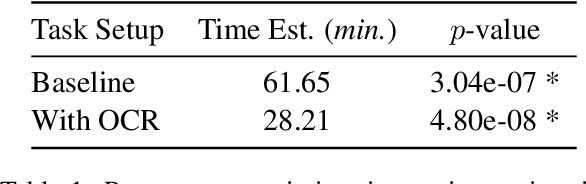


There has been recent interest in improving optical character recognition (OCR) for endangered languages, particularly because a large number of documents and books in these languages are not in machine-readable formats. The performance of OCR systems is typically evaluated using automatic metrics such as character and word error rates. While error rates are useful for the comparison of different models and systems, they do not measure whether and how the transcriptions produced from OCR tools are useful to downstream users. In this paper, we present a human-centric evaluation of OCR systems, focusing on the Kwak'wala language as a case study. With a user study, we show that utilizing OCR reduces the time spent in the manual transcription of culturally valuable documents -- a task that is often undertaken by endangered language community members and researchers -- by over 50%. Our results demonstrate the potential benefits that OCR tools can have on downstream language documentation and revitalization efforts.
Lexically Aware Semi-Supervised Learning for OCR Post-Correction
Nov 04, 2021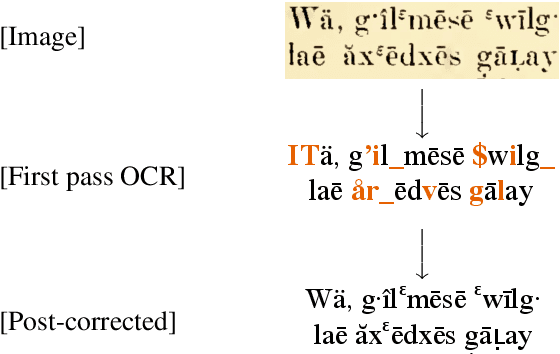
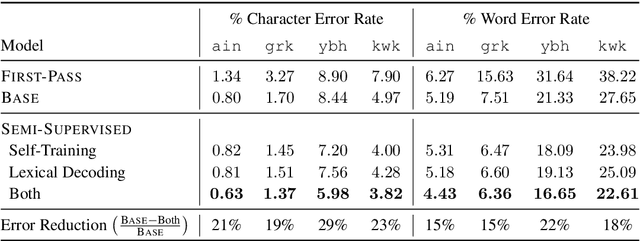
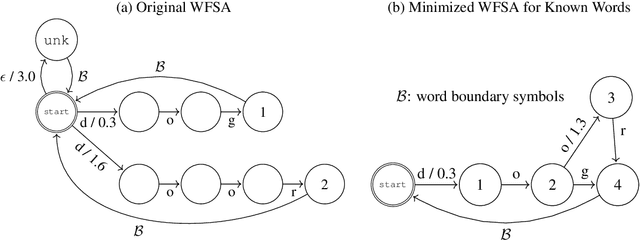

Much of the existing linguistic data in many languages of the world is locked away in non-digitized books and documents. Optical character recognition (OCR) can be used to produce digitized text, and previous work has demonstrated the utility of neural post-correction methods that improve the results of general-purpose OCR systems on recognition of less-well-resourced languages. However, these methods rely on manually curated post-correction data, which are relatively scarce compared to the non-annotated raw images that need to be digitized. In this paper, we present a semi-supervised learning method that makes it possible to utilize these raw images to improve performance, specifically through the use of self-training, a technique where a model is iteratively trained on its own outputs. In addition, to enforce consistency in the recognized vocabulary, we introduce a lexically-aware decoding method that augments the neural post-correction model with a count-based language model constructed from the recognized texts, implemented using weighted finite-state automata (WFSA) for efficient and effective decoding. Results on four endangered languages demonstrate the utility of the proposed method, with relative error reductions of 15-29%, where we find the combination of self-training and lexically-aware decoding essential for achieving consistent improvements. Data and code are available at https://shrutirij.github.io/ocr-el/.