 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaDeR: A New Task Dependency Recommendation for Project Management Platform
May 12, 2022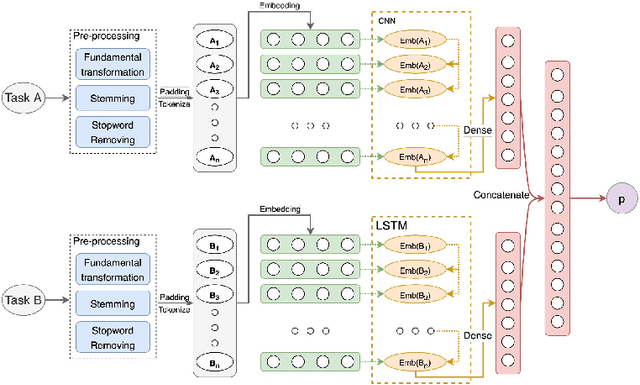
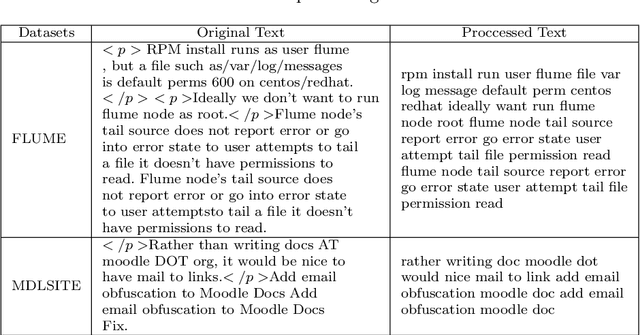
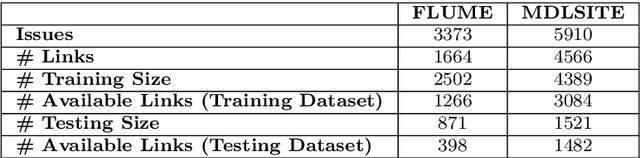
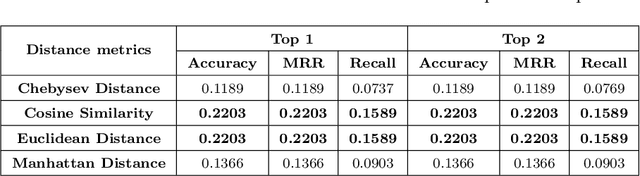
Many startups and companies worldwide have been using project management software and tools to monitor, track and manage their projects. For software projects, the number of tasks from the beginning to the end is quite a large number that sometimes takes a lot of time and effort to search and link the current task to a group of previous ones for further references. This paper proposes an efficient task dependency recommendation algorithm to suggest tasks dependent on a given task that the user has just created. We present an efficient feature engineering step and construct a deep neural network to this aim. We performed extensive experiments on two different large projects (MDLSITE from moodle.org and FLUME from apache.org) to find the best features in 28 combinations of features and the best performance model using two embedding methods (GloVe and FastText). We consider three types of models (GRU, CNN, LSTM) using Accuracy@K, MRR@K, and Recall@K (where K = 1, 2, 3, and 5) and baseline models using traditional methods: TF-IDF with various matching score calculating such as cosine similarity, Euclidean distance, Manhattan distance, and Chebyshev distance. After many experiments, the GloVe Embedding and CNN model reached the best result in our dataset, so we chose this model as our proposed method. In addition, adding the time filter in the post-processing step can significantly improve the recommendation system's performance. The experimental results show that our proposed method can reach 0.2335 in Accuracy@1 and MRR@1 and 0.2011 in Recall@1 of dataset FLUME. With the MDLSITE dataset, we obtained 0.1258 in Accuracy@1 and MRR@1 and 0.1141 in Recall@1. In the top 5, our model reached 0.3040 in Accuracy@5, 0.2563 MRR@5, and 0.2651 Recall@5 in FLUME. In the MDLSITE dataset, our model got 0.5270 Accuracy@5, 0.2689 MRR@5, and 0.2651 Recall@5.
FPSRS: A Fusion Approach for Paper Submission Recommendation System
May 12, 2022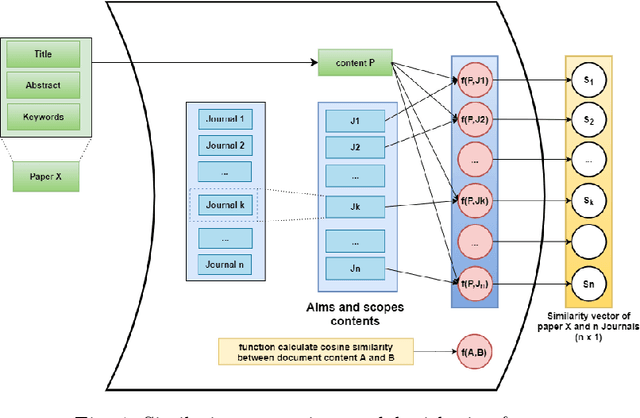
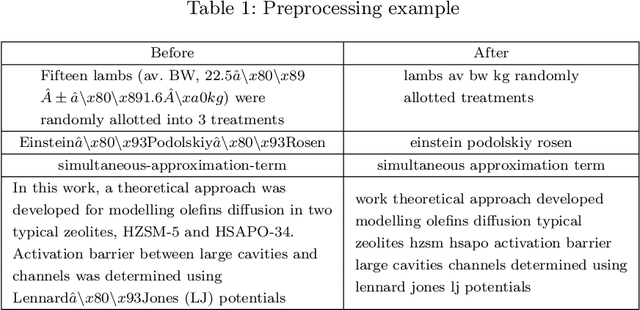

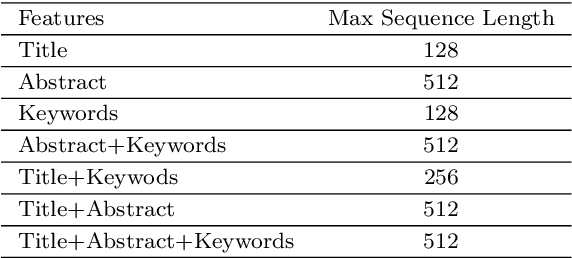
Recommender systems have been increasingly popular in entertainment and consumption and are evident in academics, especially for applications that suggest submitting scientific articles to scientists. However, because of the various acceptance rates, impact factors, and rankings in different publishers, searching for a proper venue or journal to submit a scientific work usually takes a lot of time and effort. In this paper, we aim to present two newer approaches extended from our paper [13] presented at the conference IAE/AIE 2021 by employing RNN structures besides using Conv1D. In addition, we also introduce a new method, namely DistilBertAims, using DistillBert for two cases of uppercase and lower-case words to vectorize features such as Title, Abstract, and Keywords, and then use Conv1d to perform feature extraction. Furthermore, we propose a new calculation method for similarity score for Aim & Scope with other features; this helps keep the weights of similarity score calculation continuously updated and then continue to fit more data. The experimental results show that the second approach could obtain a better performance, which is 62.46% and 12.44% higher than the best of the previous study [13] in terms of the Top 1 accuracy.