 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the gap: Exact maximum likelihood training of generative autoencoders using invertible layers
May 19, 2022

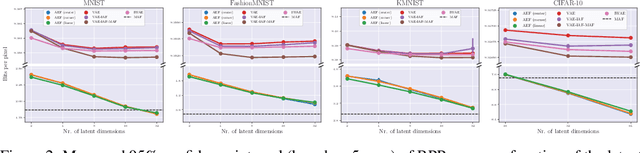

In this work, we provide an exact likelihood alternative to the variational training of generative autoencoders. We show that VAE-style autoencoders can be constructed using invertible layers, which offer a tractable exact likelihood without the need for any regularization terms. This is achieved while leaving complete freedom in the choice of encoder, decoder and prior architectures, making our approach a drop-in replacement for the training of existing VAEs and VAE-style models. We refer to the resulting models as Autoencoders within Flows (AEF), since the encoder, decoder and prior are defined as individual layers of an overall invertible architecture. We show that the approach results in strikingly higher performance than architecturally equivalent VAEs in term of log-likelihood, sample quality and denoising performance. In a broad sense, the main ambition of this work is to close the gap between the normalizing flow and autoencoder literature under the common framework of invertibility and exact maximum likelihood.