 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying (Hyper) Parameter Leakage in Machine Learning
Oct 31, 2019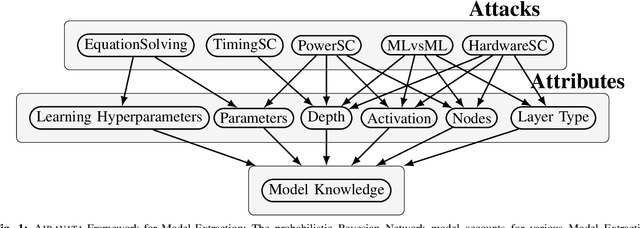
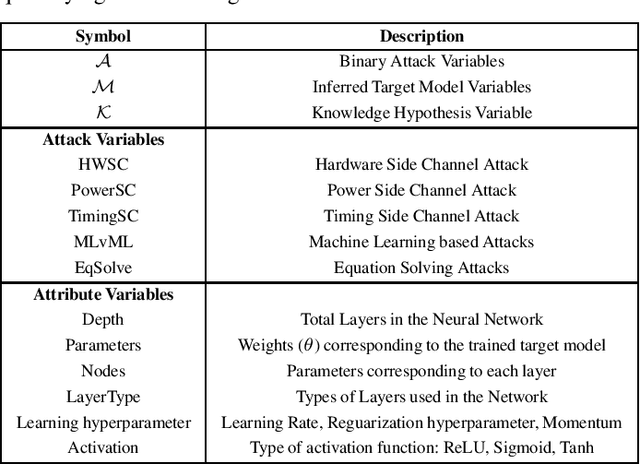
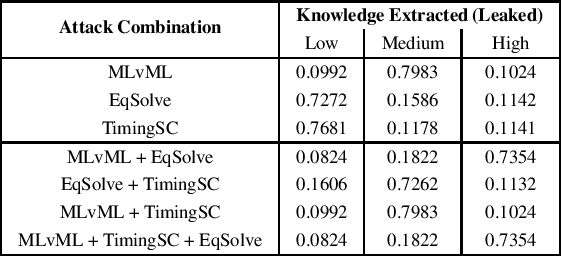
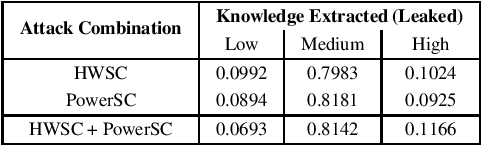
Black Box Machine Learning models leak information about the proprietary model parameters and architecture, both through side channels and output predictions. An adversary can thus, exploit this leakage to reconstruct a substitute architecture similar to the target model, violating the model privacy and Intellectual Property. However, all such attacks, infer a subset of the target model attributes and identifying the rest of the architecture and parameters (optimally) is a search problem. Extracting the exact target model is not possible owing to the uncertainty in the inference attack outputs and stochastic nature of the training process. In this work, we propose a probabilistic framework, Airavata, to estimate the leakage in such model extraction attacks. Specifically, we use Bayesian Networks to capture the uncertainty, under the subjective notion of probability, in estimating the target model attributes using various model extraction attacks. We experimentally validate the model under different adversary assumptions commonly adopted by various model extraction attacks to reason about the attack efficacy. Further, this provides a practical approach of inferring actionable knowledge about extracting black box models and identify the best combination of attacks which maximise the knowledge extracted (information leaked) from the target model.
Fault Tolerance of Neural Networks in Adversarial Settings
Oct 30, 2019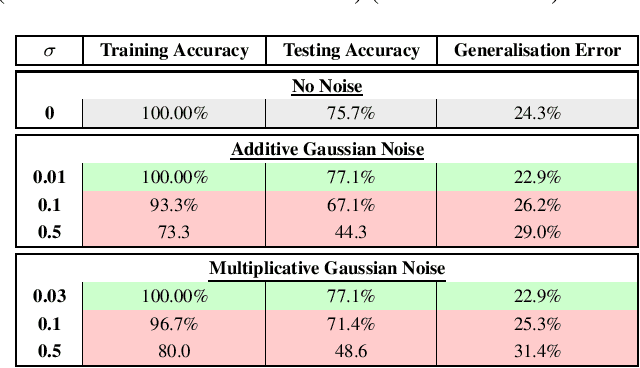
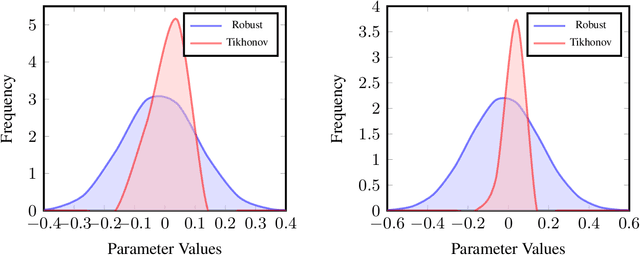

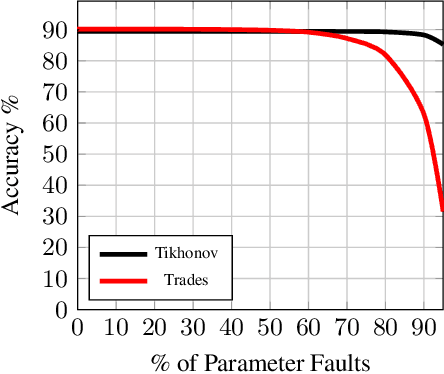
Artificial Intelligence systems require a through assessment of different pillars of trust, namely, fairness, interpretability, data and model privacy, reliability (safety) and robustness against against adversarial attacks. While these research problems have been extensively studied in isolation, an understanding of the trade-off between different pillars of trust is lacking. To this extent, the trade-off between fault tolerance, privacy and adversarial robustness is evaluated for the specific case of Deep Neural Networks, by considering two adversarial settings under a security and a privacy threat model. Specifically, this work studies the impact of the fault tolerance of the Neural Network on training the model by adding noise to the input (Adversarial Robustness) and noise to the gradients (Differential Privacy). While training models with noise to inputs, gradients or weights enhances fault tolerance, it is observed that adversarial robustness and fault tolerance are at odds with each other. On the other hand, ($\epsilon,\delta$)-Differentially Private models enhance the fault tolerance, measured using generalisation error, theoretically has an upper bound of $e^{\epsilon} - 1 + \delta$. This novel study of the trade-off between different elements of trust is pivotal for training a model which satisfies the requirements for different pillars of trust simultaneously.
Adversarial Fault Tolerant Training for Deep Neural Networks
Jul 09, 2019
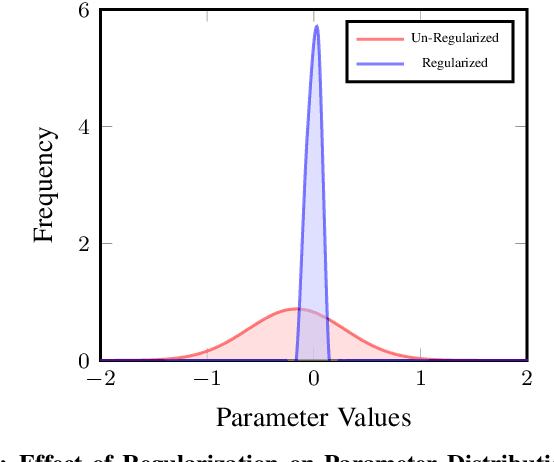
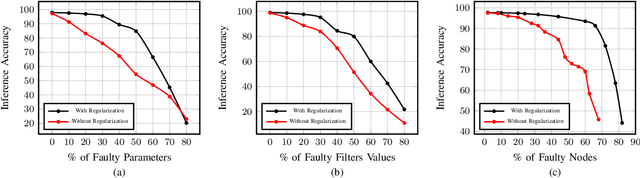
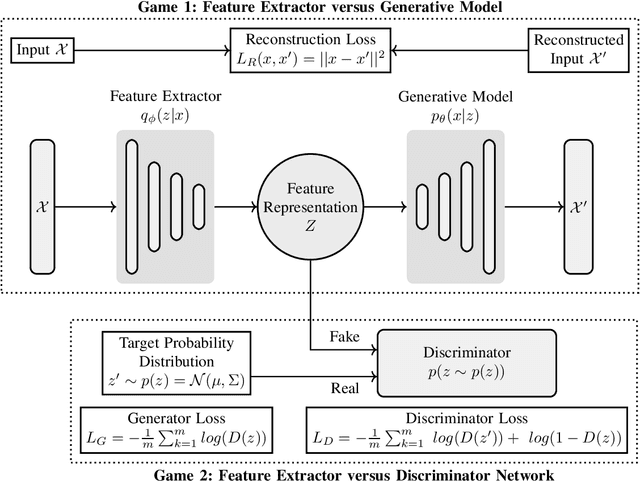
Deep Learning Accelerators are prone to faults which manifest in the form of errors in Neural Networks. Fault Tolerance in Neural Networks is crucial in real-time safety critical applications requiring computation for long durations. Neural Networks with high regularisation exhibit superior fault tolerance, however, at the cost of classification accuracy. In the view of difference in functionality, a Neural Network is modelled as two separate networks, i.e, the Feature Extractor with unsupervised learning objective and the Classifier with a supervised learning objective. Traditional approaches of training the entire network using a single supervised learning objective is insufficient to achieve the objectives of the individual components optimally. In this work, a novel multi-criteria objective function, combining unsupervised training of the Feature Extractor followed by supervised tuning with Classifier Network is proposed. The unsupervised training solves two games simultaneously in the presence of adversary neural networks with conflicting objectives to the Feature Extractor. The first game minimises the loss in reconstructing the input image for indistinguishability given the features from the Extractor, in the presence of a generative decoder. The second game solves a minimax constraint optimisation for distributional smoothening of feature space to match a prior distribution, in the presence of a Discriminator network. The resultant strongly regularised Feature Extractor is combined with the Classifier Network for supervised fine-tuning. The proposed Adversarial Fault Tolerant Neural Network Training is scalable to large networks and is independent of the architecture. The evaluation on benchmarking datasets: FashionMNIST and CIFAR10, indicates that the resultant networks have high accuracy with superior tolerance to stuck at "0" faults compared to widely used regularisers.