 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying (Hyper) Parameter Leakage in Machine Learning
Paper and Code
Oct 31, 2019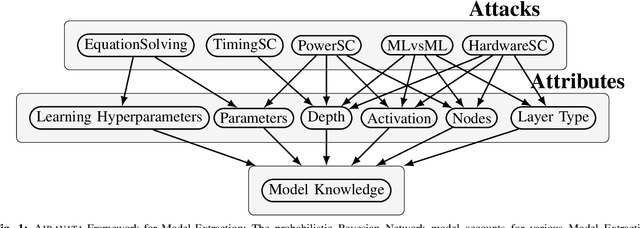
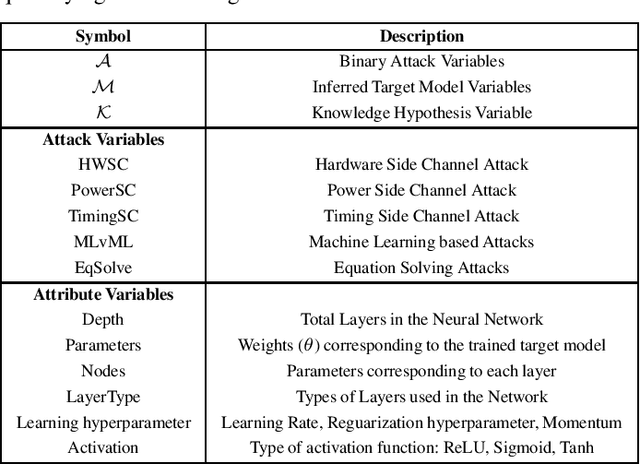
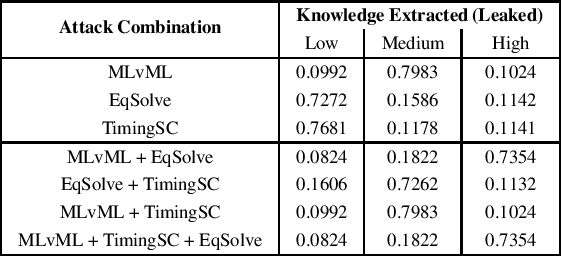
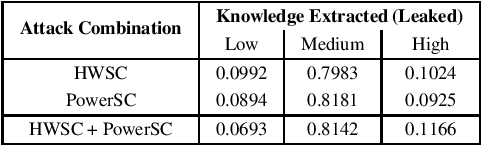
Black Box Machine Learning models leak information about the proprietary model parameters and architecture, both through side channels and output predictions. An adversary can thus, exploit this leakage to reconstruct a substitute architecture similar to the target model, violating the model privacy and Intellectual Property. However, all such attacks, infer a subset of the target model attributes and identifying the rest of the architecture and parameters (optimally) is a search problem. Extracting the exact target model is not possible owing to the uncertainty in the inference attack outputs and stochastic nature of the training process. In this work, we propose a probabilistic framework, Airavata, to estimate the leakage in such model extraction attacks. Specifically, we use Bayesian Networks to capture the uncertainty, under the subjective notion of probability, in estimating the target model attributes using various model extraction attacks. We experimentally validate the model under different adversary assumptions commonly adopted by various model extraction attacks to reason about the attack efficacy. Further, this provides a practical approach of inferring actionable knowledge about extracting black box models and identify the best combination of attacks which maximise the knowledge extracted (information leaked) from the target model.