 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNCA: A Neutrosophic-Based Framework for Robust Clustering and Enhanced Data Interpretation
Feb 23, 2025Accurately representing the complex linkages and inherent uncertainties included in huge datasets is still a major difficulty in the field of data clustering. We address these issues with our proposed Unified Neutrosophic Clustering Algorithm (UNCA), which combines a multifaceted strategy with Neutrosophic logic to improve clustering performance. UNCA starts with a full-fledged similarity examination via a {\lambda}-cutting matrix that filters meaningful relationships between each two points of data. Then, we initialize centroids for Neutrosophic K-Means clustering, where the membership values are based on their degrees of truth, indeterminacy and falsity. The algorithm then integrates with a dynamic network visualization and MST (Minimum Spanning Tree) so that a visual interpretation of the relationships between the clusters can be clearly represented. UNCA employs SingleValued Neutrosophic Sets (SVNSs) to refine cluster assignments, and after fuzzifying similarity measures, guarantees a precise clustering result. The final step involves solidifying the clustering results through defuzzification methods, offering definitive cluster assignments. According to the performance evaluation results, UNCA outperforms conventional approaches in several metrics: it achieved a Silhouette Score of 0.89 on the Iris Dataset, a Davies-Bouldin Index of 0.59 on the Wine Dataset, an Adjusted Rand Index (ARI) of 0.76 on the Digits Dataset, and a Normalized Mutual Information (NMI) of 0.80 on the Customer Segmentation Dataset. These results demonstrate how UNCA enhances interpretability and resilience in addition to improving clustering accuracy when contrasted with Fuzzy C-Means (FCM), Neutrosophic C-Means (NCM), as well as Kernel Neutrosophic C-Means (KNCM). This makes UNCA a useful tool for complex data processing tasks
Leveraging Semi-Supervised Graph Learning for Enhanced Diabetic Retinopathy Detection
Sep 02, 2023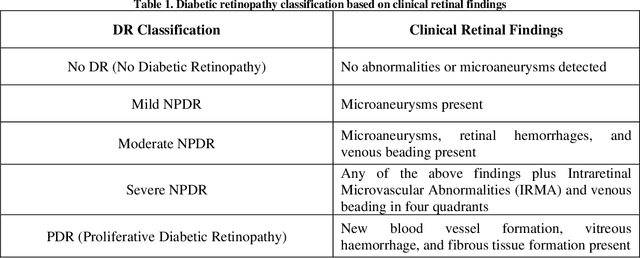
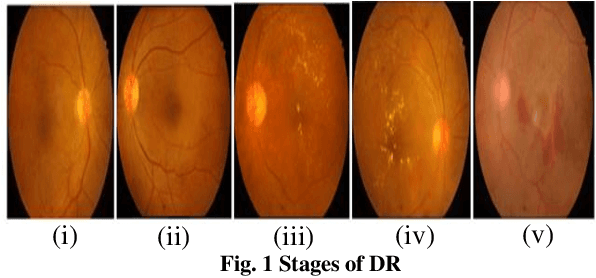
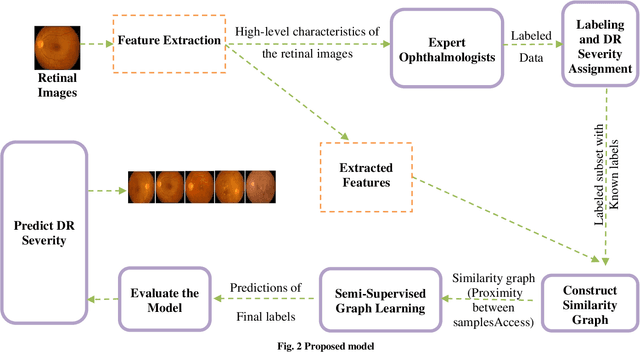
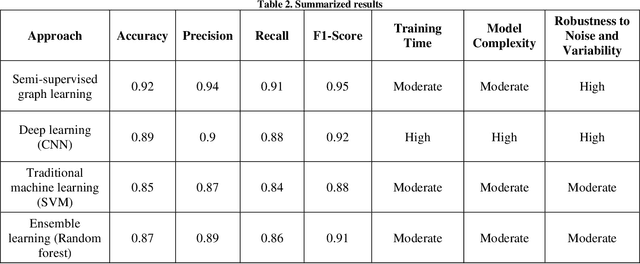
Diabetic Retinopathy (DR) is a significant cause of blindness globally, highlighting the urgent need for early detection and effective treatment. Recent advancements in Machine Learning (ML) techniques have shown promise in DR detection, but the availability of labeled data often limits their performance. This research proposes a novel Semi-Supervised Graph Learning SSGL algorithm tailored for DR detection, which capitalizes on the relationships between labelled and unlabeled data to enhance accuracy. The work begins by investigating data augmentation and preprocessing techniques to address the challenges of image quality and feature variations. Techniques such as image cropping, resizing, contrast adjustment, normalization, and data augmentation are explored to optimize feature extraction and improve the overall quality of retinal images. Moreover, apart from detection and diagnosis, this work delves into applying ML algorithms for predicting the risk of developing DR or the likelihood of disease progression. Personalized risk scores for individual patients are generated using comprehensive patient data encompassing demographic information, medical history, and retinal images. The proposed Semi-Supervised Graph learning algorithm is rigorously evaluated on two publicly available datasets and is benchmarked against existing methods. Results indicate significant improvements in classification accuracy, specificity, and sensitivity while demonstrating robustness against noise and outlie rs.Notably, the proposed algorithm addresses the challenge of imbalanced datasets, common in medical image analysis, further enhancing its practical applicability.