 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit-wise Training of Neural Network Weights
Feb 19, 2022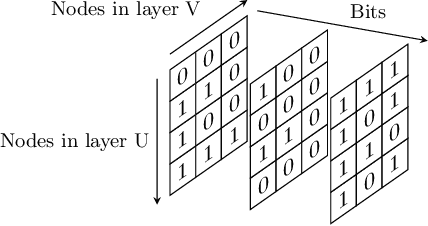

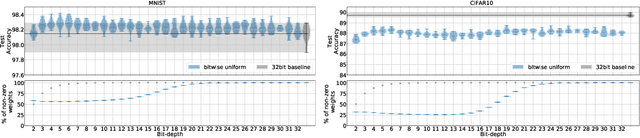

We introduce an algorithm where the individual bits representing the weights of a neural network are learned. This method allows training weights with integer values on arbitrary bit-depths and naturally uncovers sparse networks, without additional constraints or regularization techniques. We show better results than the standard training technique with fully connected networks and similar performance as compared to standard training for convolutional and residual networks. By training bits in a selective manner we found that the biggest contribution to achieving high accuracy is given by the first three most significant bits, while the rest provide an intrinsic regularization. As a consequence more than 90\% of a network can be used to store arbitrary codes without affecting its accuracy. These codes may be random noise, binary files or even the weights of previously trained networks.
Training highly effective connectivities within neural networks with randomly initialized, fixed weights
Jun 30, 2020
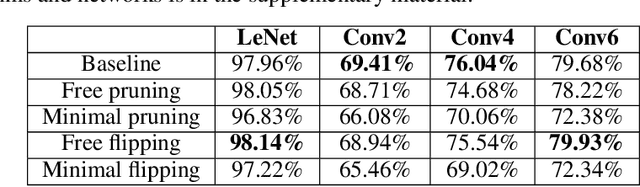
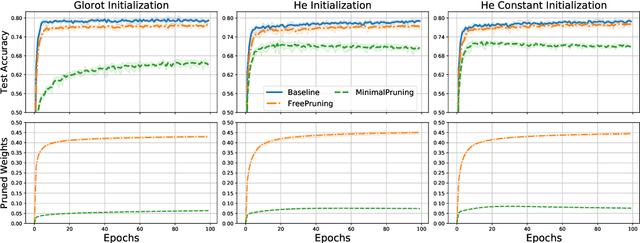
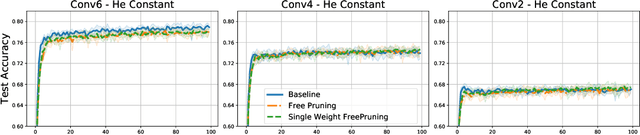
We present some novel, straightforward methods for training the connection graph of a randomly initialized neural network without training the weights. These methods do not use hyperparameters defining cutoff thresholds and therefore remove the need for iteratively searching optimal values of such hyperparameters. We can achieve similar or higher performances than in the case of training all weights, with a similar computational cost as for standard training techniques. Besides switching connections on and off, we introduce a novel way of training a network by flipping the signs of the weights. If we try to minimize the number of changed connections, by changing less than 10\% of the total it is already possible to reach more than 90\% of the accuracy achieved by standard training. We obtain good results even with weights of constant magnitude or even when weights are drawn from highly asymmetric distributions. These results shed light on the over-parameterization of neural networks and on how they may be reduced to their effective size.
Convolutional Neural Networks on Randomized Data
Jul 25, 2019
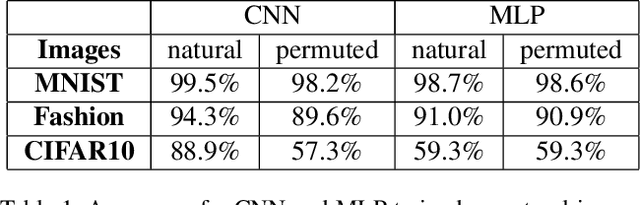
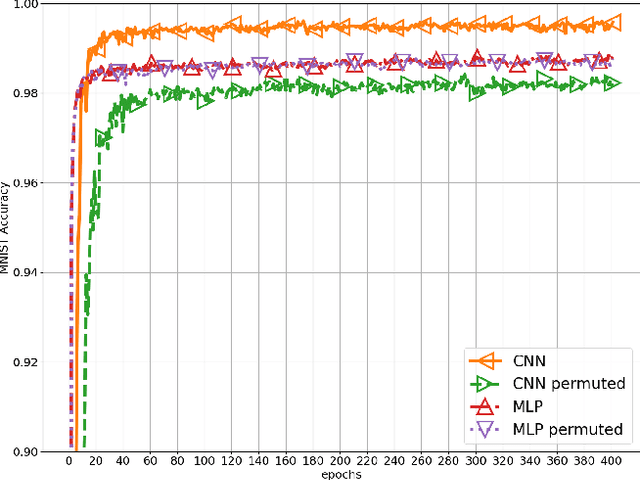
Convolutional Neural Networks (CNNs) are build specifically for computer vision tasks for which it is known that the input data is a hierarchical structure based on locally correlated elements. The question that naturally arises is what happens with the performance of CNNs if one of the basic properties of the data is removed, e.g. what happens if the image pixels are randomly permuted? Intuitively one expects that the convolutional network performs poorly in these circumstances in contrast to a multilayer perceptron (MLPs) whose classification accuracy should not be affected by the pixel randomization. This work shows that by randomizing image pixels the hierarchical structure of the data is destroyed and long range correlations are introduced which standard CNNs are not able to capture. We show that their classification accuracy is heavily dependent on the class similarities as well as the pixel randomization process. We also indicate that dilated convolutions are able to recover some of the pixel correlations and improve the performance.
* 8 pages, 17 figures, presented at Deep-Vision workshop, CVPR 2019
On modelling the emergence of logical thinking
May 23, 2019Recent progress in machine learning techniques have revived interest in building artificial general intelligence using these particular tools. There has been a tremendous success in applying them for narrow intellectual tasks such as pattern recognition, natural language processing and playing Go. The latter application vastly outperforms the strongest human player in recent years. However, these tasks are formalized by people in such ways that it has become "easy" for automated recipes to find better solutions than humans do. In the sense of John Searle's Chinese Room Argument, the computer playing Go does not actually understand anything from the game. Thinking like a human mind requires to go beyond the curve fitting paradigm of current systems. There is a fundamental limit to what they can achieve currently as only very specific problem formalization can increase their performances in particular tasks. In this paper, we argue than one of the most important aspects of the human mind is its capacity for logical thinking, which gives rise to many intellectual expressions that differentiate us from animal brains. We propose to model the emergence of logical thinking based on Piaget's theory of cognitive development.