 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining highly effective connectivities within neural networks with randomly initialized, fixed weights
Paper and Code

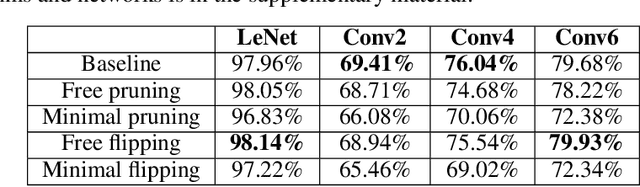
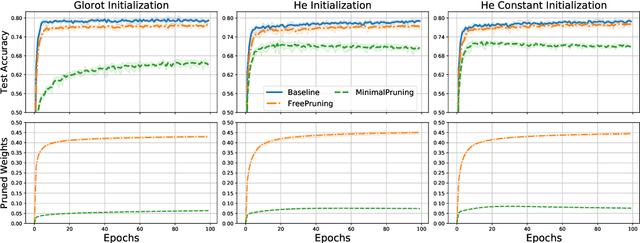
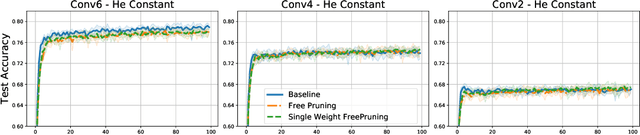
We present some novel, straightforward methods for training the connection graph of a randomly initialized neural network without training the weights. These methods do not use hyperparameters defining cutoff thresholds and therefore remove the need for iteratively searching optimal values of such hyperparameters. We can achieve similar or higher performances than in the case of training all weights, with a similar computational cost as for standard training techniques. Besides switching connections on and off, we introduce a novel way of training a network by flipping the signs of the weights. If we try to minimize the number of changed connections, by changing less than 10\% of the total it is already possible to reach more than 90\% of the accuracy achieved by standard training. We obtain good results even with weights of constant magnitude or even when weights are drawn from highly asymmetric distributions. These results shed light on the over-parameterization of neural networks and on how they may be reduced to their effective size.