 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks on Randomized Data
Paper and Code
Jul 25, 2019
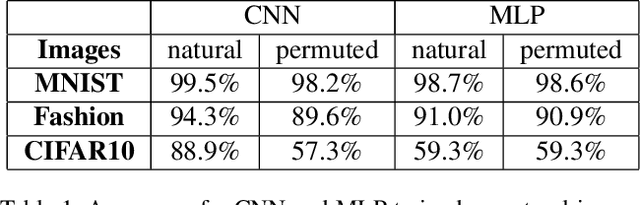
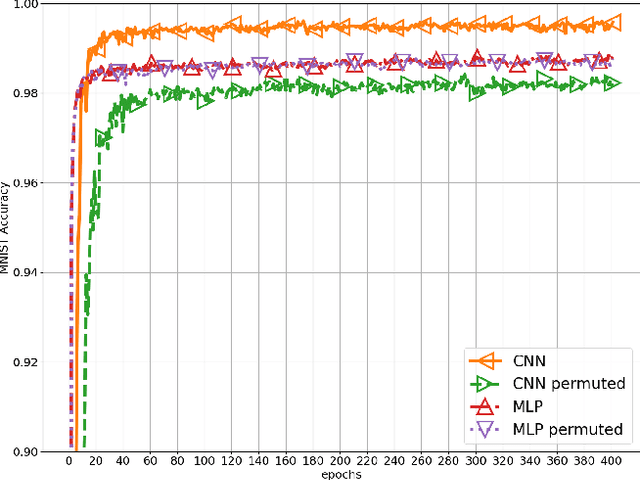
Convolutional Neural Networks (CNNs) are build specifically for computer vision tasks for which it is known that the input data is a hierarchical structure based on locally correlated elements. The question that naturally arises is what happens with the performance of CNNs if one of the basic properties of the data is removed, e.g. what happens if the image pixels are randomly permuted? Intuitively one expects that the convolutional network performs poorly in these circumstances in contrast to a multilayer perceptron (MLPs) whose classification accuracy should not be affected by the pixel randomization. This work shows that by randomizing image pixels the hierarchical structure of the data is destroyed and long range correlations are introduced which standard CNNs are not able to capture. We show that their classification accuracy is heavily dependent on the class similarities as well as the pixel randomization process. We also indicate that dilated convolutions are able to recover some of the pixel correlations and improve the performance.