 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling with Information Relaxation Penalties
Feb 12, 2019

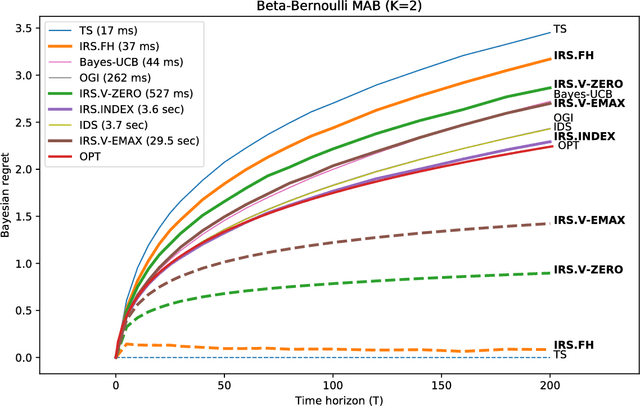
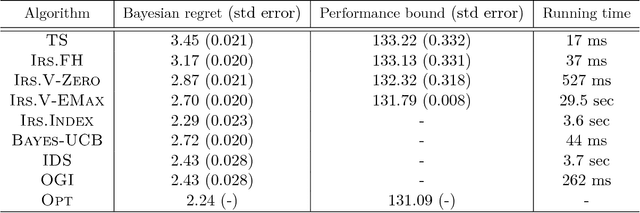
We consider a finite time horizon multi-armed bandit (MAB) problem in a Bayesian framework, for which we develop a general set of control policies that leverage ideas from information relaxations of stochastic dynamic optimization problems. In crude terms, an information relaxation allows the decision maker (DM) to have access to the future (unknown) rewards and incorporate them in her optimization problem to pick an action at time $t$, but penalizes the decision maker for using this information. In our setting, the future rewards allow the DM to better estimate the unknown mean reward parameters of the multiple arms, and optimize her sequence of actions. By picking different information penalties, the DM can construct a family of policies of increasing complexity that, for example, include Thompson Sampling and the true optimal (but intractable) policy as special cases. We systematically develop this framework of information relaxation sampling, propose an intuitive family of control policies for our motivating finite time horizon Bayesian MAB problem, and prove associated structural results and performance bounds. Numerical experiments suggest that this new class of policies performs well, in particular in settings where the finite time horizon introduces significant tension in the problem. Finally, inspired by the finite time horizon Gittins index, we propose an index policy that builds on our framework that particularly outperforms to the state-of-the-art algorithms in our numerical experiments.