 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess Supervision for Chain-of-Thought Reasoning via Monte Carlo Net Information Gain
Mar 18, 2026Multi-step reasoning improves the capabilities of large language models (LLMs) but increases the risk of errors propagating through intermediate steps. Process reward models (PRMs) mitigate this by scoring each step individually, enabling fine-grained supervision and improved reliability. Existing methods for training PRMs rely on costly human annotations or computationally intensive automatic labeling. We propose a novel approach to automatically generate step-level labels using Information Theory. Our method estimates how each reasoning step affects the likelihood of the correct answer, providing a signal of step quality. Importantly, it reduces computational complexity to $\mathcal{O}(N)$, improving over the previous $\mathcal{O}(N \log N)$ methods. We demonstrate that these labels enable effective chain-of-thought selection in best-of-$K$ evaluation settings across diverse reasoning benchmarks, including mathematics, Python programming, SQL, and scientific question answering. This work enables scalable and efficient supervision of LLM reasoning, particularly for tasks where error propagation is critical.
DeViDe: Faceted medical knowledge for improved medical vision-language pre-training
Apr 04, 2024Vision-language pre-training for chest X-rays has made significant strides, primarily by utilizing paired radiographs and radiology reports. However, existing approaches often face challenges in encoding medical knowledge effectively. While radiology reports provide insights into the current disease manifestation, medical definitions (as used by contemporary methods) tend to be overly abstract, creating a gap in knowledge. To address this, we propose DeViDe, a novel transformer-based method that leverages radiographic descriptions from the open web. These descriptions outline general visual characteristics of diseases in radiographs, and when combined with abstract definitions and radiology reports, provide a holistic snapshot of knowledge. DeViDe incorporates three key features for knowledge-augmented vision language alignment: First, a large-language model-based augmentation is employed to homogenise medical knowledge from diverse sources. Second, this knowledge is aligned with image information at various levels of granularity. Third, a novel projection layer is proposed to handle the complexity of aligning each image with multiple descriptions arising in a multi-label setting. In zero-shot settings, DeViDe performs comparably to fully supervised models on external datasets and achieves state-of-the-art results on three large-scale datasets. Additionally, fine-tuning DeViDe on four downstream tasks and six segmentation tasks showcases its superior performance across data from diverse distributions.
MultiMedEval: A Benchmark and a Toolkit for Evaluating Medical Vision-Language Models
Feb 16, 2024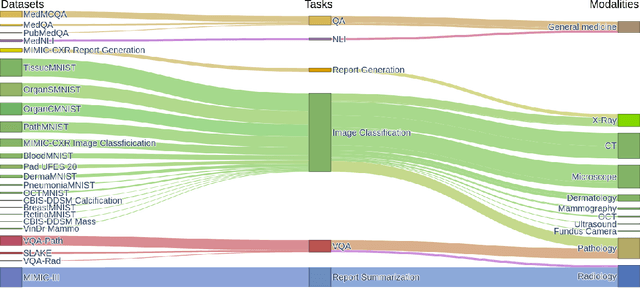

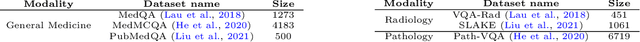
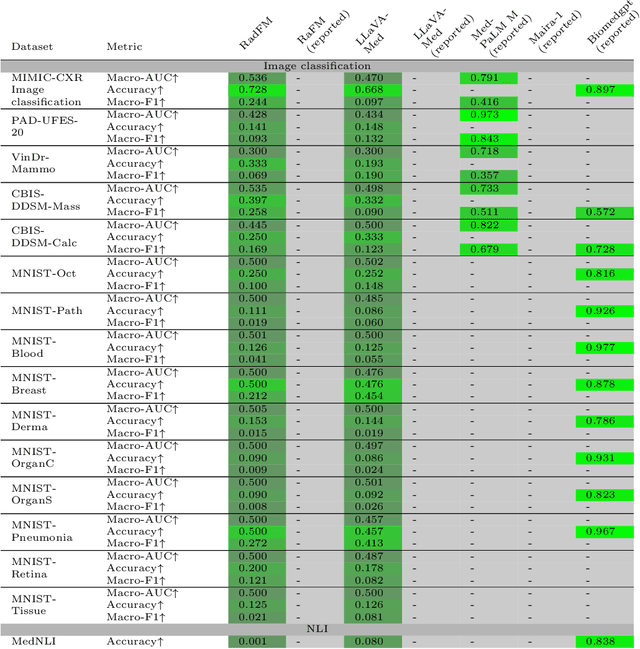
We introduce MultiMedEval, an open-source toolkit for fair and reproducible evaluation of large, medical vision-language models (VLM). MultiMedEval comprehensively assesses the models' performance on a broad array of six multi-modal tasks, conducted over 23 datasets, and spanning over 11 medical domains. The chosen tasks and performance metrics are based on their widespread adoption in the community and their diversity, ensuring a thorough evaluation of the model's overall generalizability. We open-source a Python toolkit (github.com/corentin-ryr/MultiMedEval) with a simple interface and setup process, enabling the evaluation of any VLM in just a few lines of code. Our goal is to simplify the intricate landscape of VLM evaluation, thus promoting fair and uniform benchmarking of future models.