 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sample $ζ$-mixup: Richer, More Realistic Synthetic Samples from a $p$-Series Interpolant
Apr 07, 2022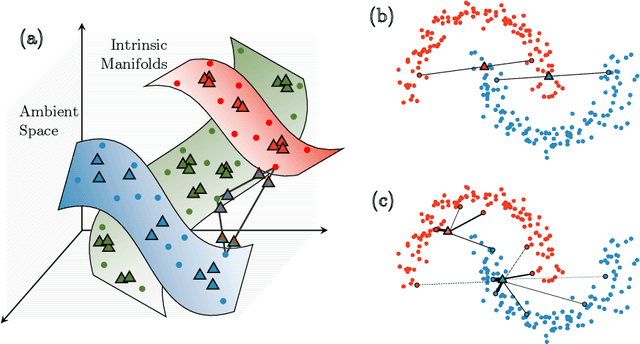

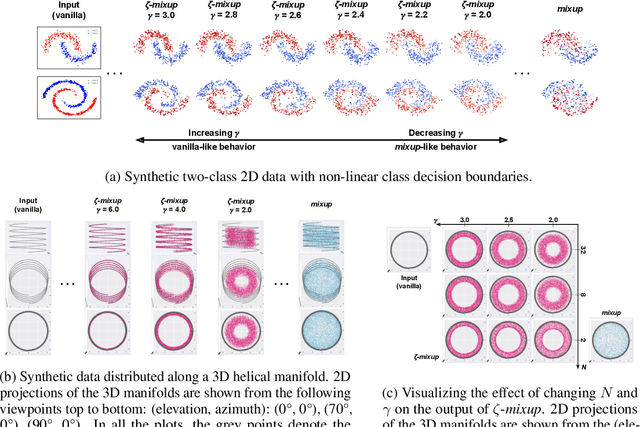
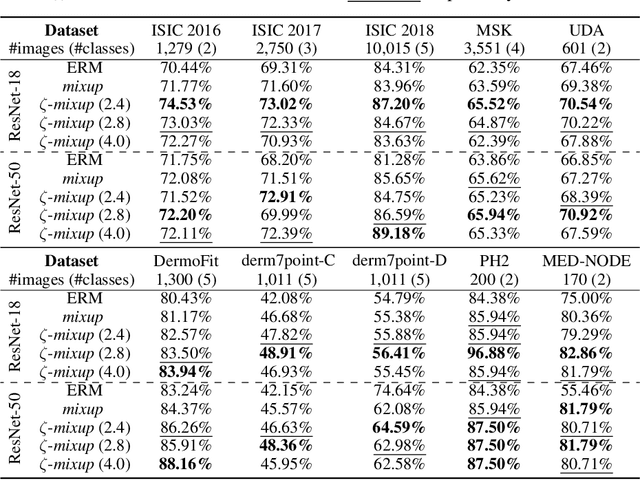
Modern deep learning training procedures rely on model regularization techniques such as data augmentation methods, which generate training samples that increase the diversity of data and richness of label information. A popular recent method, mixup, uses convex combinations of pairs of original samples to generate new samples. However, as we show in our experiments, mixup can produce undesirable synthetic samples, where the data is sampled off the manifold and can contain incorrect labels. We propose $\zeta$-mixup, a generalization of mixup with provably and demonstrably desirable properties that allows convex combinations of $N \geq 2$ samples, leading to more realistic and diverse outputs that incorporate information from $N$ original samples by using a $p$-series interpolant. We show that, compared to mixup, $\zeta$-mixup better preserves the intrinsic dimensionality of the original datasets, which is a desirable property for training generalizable models. Furthermore, we show that our implementation of $\zeta$-mixup is faster than mixup, and extensive evaluation on controlled synthetic and 24 real-world natural and medical image classification datasets shows that $\zeta$-mixup outperforms mixup and traditional data augmentation techniques.