 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quantifier-Reversal Approximation Paradigm for Recurrent Neural Networks
Nov 19, 2025Classical neural network approximation results take the form: for every function $f$ and every error tolerance $ε> 0$, one constructs a neural network whose architecture and weights depend on $ε$. This paper introduces a fundamentally different approximation paradigm that reverses this quantifier order. For each target function $f$, we construct a single recurrent neural network (RNN) with fixed topology and fixed weights that approximates $f$ to within any prescribed tolerance $ε> 0$ when run for sufficiently many time steps. The key mechanism enabling this quantifier reversal is temporal computation combined with weight sharing: rather than increasing network depth, the approximation error is reduced solely by running the RNN longer. This yields exponentially decaying approximation error as a function of runtime while requiring storage of only a small, fixed set of weights. Such architectures are appealing for hardware implementations where memory is scarce and runtime is comparatively inexpensive. To initiate the systematic development of this novel approximation paradigm, we focus on univariate polynomials. Our RNN constructions emulate the structural calculus underlying deep feed-forward ReLU network approximation theory -- parallelization, linear combinations, affine transformations, and, most importantly, a clocked mechanism that realizes function composition within a single recurrent architecture. The resulting RNNs have size independent of the error tolerance $ε$ and hidden-state dimension linear in the degree of the polynomial.
Metric-Entropy Limits on Nonlinear Dynamical System Learning
Jul 01, 2024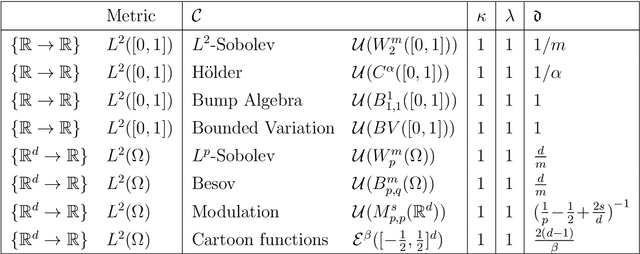


This paper is concerned with the fundamental limits of nonlinear dynamical system learning from input-output traces. Specifically, we show that recurrent neural networks (RNNs) are capable of learning nonlinear systems that satisfy a Lipschitz property and forget past inputs fast enough in a metric-entropy optimal manner. As the sets of sequence-to-sequence maps realized by the dynamical systems we consider are significantly more massive than function classes generally considered in deep neural network approximation theory, a refined metric-entropy characterization is needed, namely in terms of order, type, and generalized dimension. We compute these quantities for the classes of exponentially-decaying and polynomially-decaying Lipschitz fading-memory systems and show that RNNs can achieve them.
Metric Entropy Limits on Recurrent Neural Network Learning of Linear Dynamical Systems
May 06, 2021One of the most influential results in neural network theory is the universal approximation theorem [1, 2, 3] which states that continuous functions can be approximated to within arbitrary accuracy by single-hidden-layer feedforward neural networks. The purpose of this paper is to establish a result in this spirit for the approximation of general discrete-time linear dynamical systems - including time-varying systems - by recurrent neural networks (RNNs). For the subclass of linear time-invariant (LTI) systems, we devise a quantitative version of this statement. Specifically, measuring the complexity of the considered class of LTI systems through metric entropy according to [4], we show that RNNs can optimally learn - or identify in system-theory parlance - stable LTI systems. For LTI systems whose input-output relation is characterized through a difference equation, this means that RNNs can learn the difference equation from input-output traces in a metric-entropy optimal manner.
Knowledge transfer across cell lines using Hybrid Gaussian Process models with entity embedding vectors
Nov 27, 2020To date, a large number of experiments are performed to develop a biochemical process. The generated data is used only once, to take decisions for development. Could we exploit data of already developed processes to make predictions for a novel process, we could significantly reduce the number of experiments needed. Processes for different products exhibit differences in behaviour, typically only a subset behave similar. Therefore, effective learning on multiple product spanning process data requires a sensible representation of the product identity. We propose to represent the product identity (a categorical feature) by embedding vectors that serve as input to a Gaussian Process regression model. We demonstrate how the embedding vectors can be learned from process data and show that they capture an interpretable notion of product similarity. The improvement in performance is compared to traditional one-hot encoding on a simulated cross product learning task. All in all, the proposed method could render possible significant reductions in wet-lab experiments.