 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Unsupervised Domain Adaptation for Semantic Segmentation in the Era of Vision-Language Models
Nov 25, 2024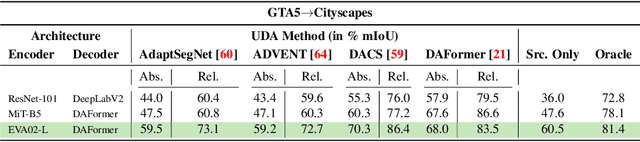
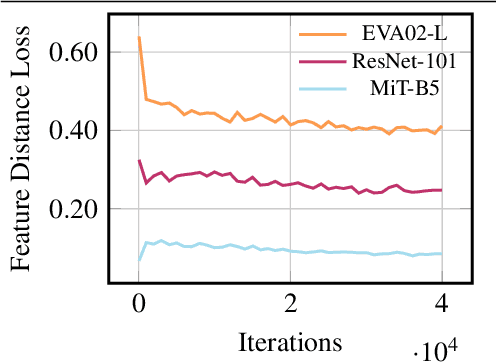
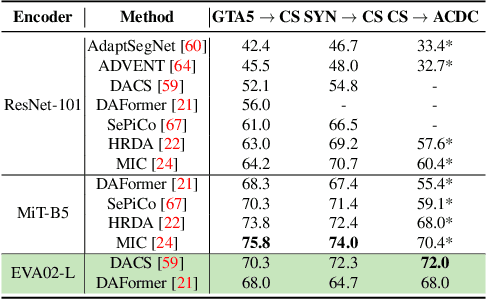
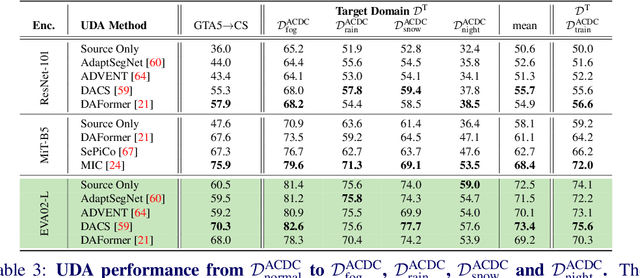
Despite the recent progress in deep learning based computer vision, domain shifts are still one of the major challenges. Semantic segmentation for autonomous driving faces a wide range of domain shifts, e.g. caused by changing weather conditions, new geolocations and the frequent use of synthetic data in model training. Unsupervised domain adaptation (UDA) methods have emerged which adapt a model to a new target domain by only using unlabeled data of that domain. The variety of UDA methods is large but all of them use ImageNet pre-trained models. Recently, vision-language models have demonstrated strong generalization capabilities which may facilitate domain adaptation. We show that simply replacing the encoder of existing UDA methods like DACS by a vision-language pre-trained encoder can result in significant performance improvements of up to 10.0% mIoU on the GTA5-to-Cityscapes domain shift. For the generalization performance to unseen domains, the newly employed vision-language pre-trained encoder provides a gain of up to 13.7% mIoU across three unseen datasets. However, we find that not all UDA methods can be easily paired with the new encoder and that the UDA performance does not always likewise transfer into generalization performance. Finally, we perform our experiments on an adverse weather condition domain shift to further verify our findings on a pure real-to-real domain shift.