 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Prediction and Interpretation in Decision Trees (PrInDT) -- a Linguistic Example
Mar 05, 2021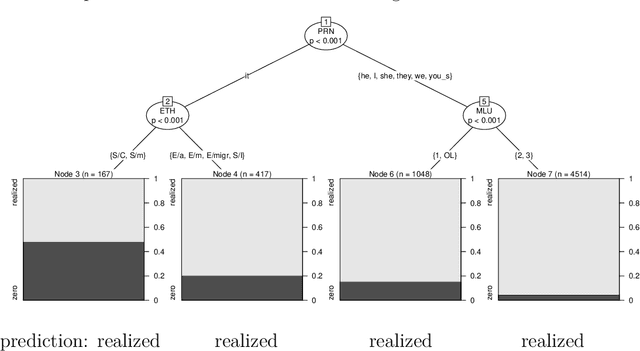
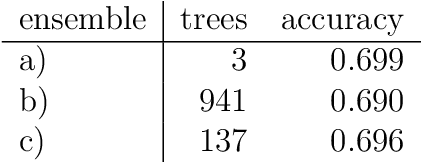

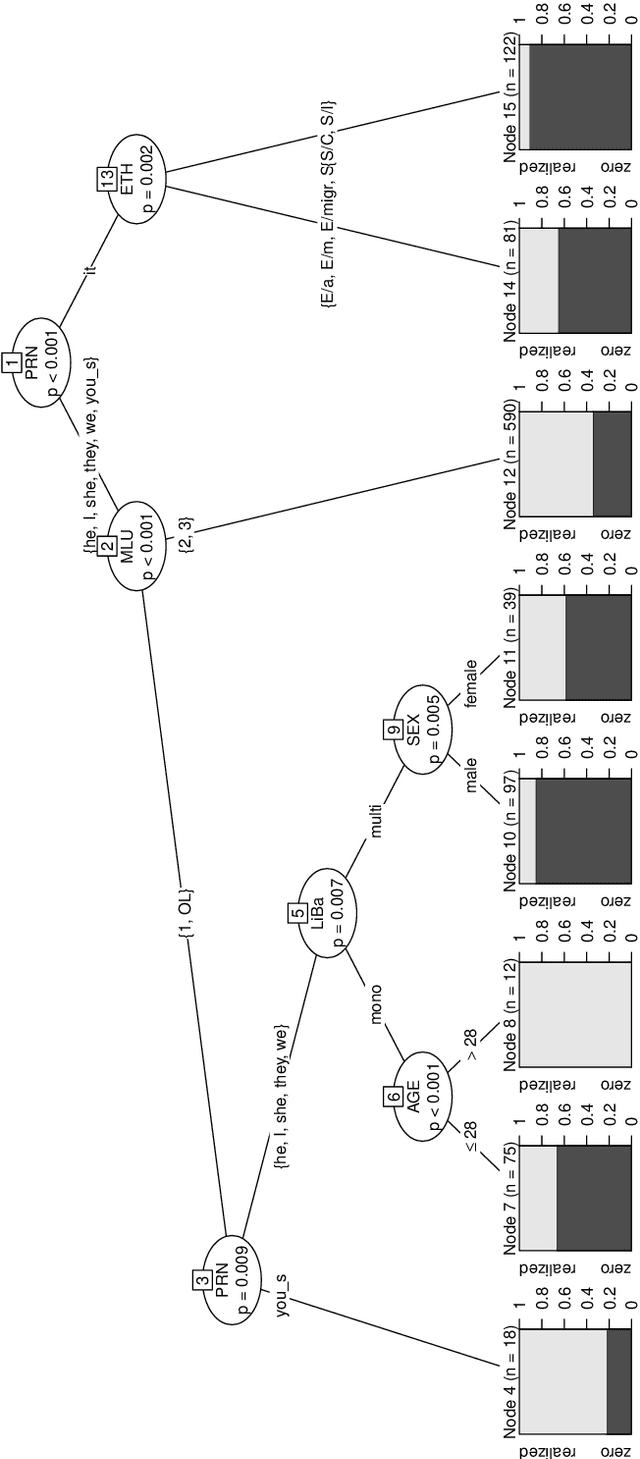
In this paper, we show that conditional inference trees and ensembles are suitable methods for modeling linguistic variation. As against earlier linguistic applications, however, we claim that their suitability is strongly increased if we combine prediction and interpretation. To that end, we have developed a statistical method, PrInDT (Prediction and Interpretation with Decision Trees), which we introduce and discuss in the present paper.
Fast model selection by limiting SVM training times
Feb 10, 2016
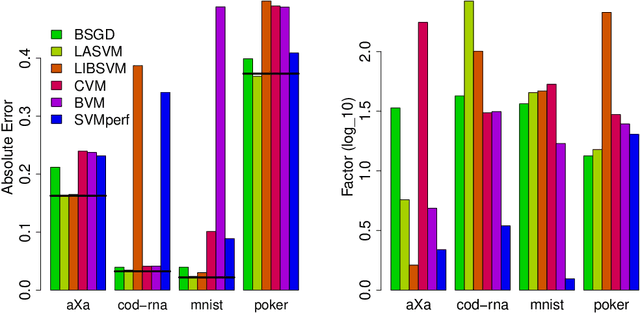
Kernelized Support Vector Machines (SVMs) are among the best performing supervised learning methods. But for optimal predictive performance, time-consuming parameter tuning is crucial, which impedes application. To tackle this problem, the classic model selection procedure based on grid-search and cross-validation was refined, e.g. by data subsampling and direct search heuristics. Here we focus on a different aspect, the stopping criterion for SVM training. We show that by limiting the training time given to the SVM solver during parameter tuning we can reduce model selection times by an order of magnitude.