 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Geometry Estimation from 360$^\circ$ Imagery: A Survey
Jan 17, 2024

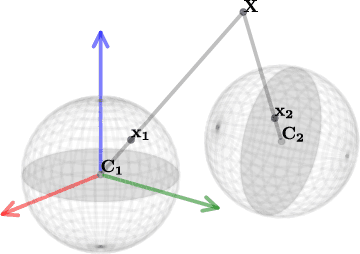
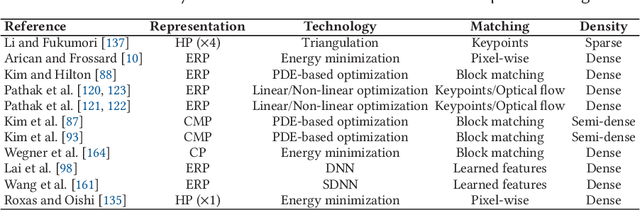
This paper provides a comprehensive survey on pioneer and state-of-the-art 3D scene geometry estimation methodologies based on single, two, or multiple images captured under the omnidirectional optics. We first revisit the basic concepts of the spherical camera model, and review the most common acquisition technologies and representation formats suitable for omnidirectional (also called 360$^\circ$, spherical or panoramic) images and videos. We then survey monocular layout and depth inference approaches, highlighting the recent advances in learning-based solutions suited for spherical data. The classical stereo matching is then revised on the spherical domain, where methodologies for detecting and describing sparse and dense features become crucial. The stereo matching concepts are then extrapolated for multiple view camera setups, categorizing them among light fields, multi-view stereo, and structure from motion (or visual simultaneous localization and mapping). We also compile and discuss commonly adopted datasets and figures of merit indicated for each purpose and list recent results for completeness. We conclude this paper by pointing out current and future trends.
* Published in ACM Computing Surveys
SVBR-NET: A Non-Blind Spatially Varying Defocus Blur Removal Network
Jun 26, 2022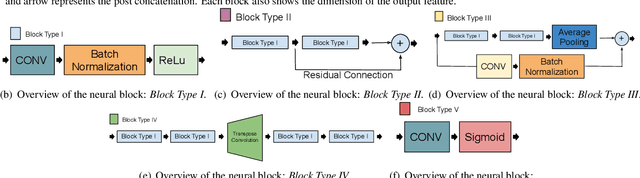



Defocus blur is a physical consequence of the optical sensors used in most cameras. Although it can be used as a photographic style, it is commonly viewed as an image degradation modeled as the convolution of a sharp image with a spatially-varying blur kernel. Motivated by the advance of blur estimation methods in the past years, we propose a non-blind approach for image deblurring that can deal with spatially-varying kernels. We introduce two encoder-decoder sub-networks that are fed with the blurry image and the estimated blur map, respectively, and produce as output the deblurred (deconvolved) image. Each sub-network presents several skip connections that allow data propagation from layers spread apart, and also inter-subnetwork skip connections that ease the communication between the modules. The network is trained with synthetically blur kernels that are augmented to emulate blur maps produced by existing blur estimation methods, and our experimental results show that our method works well when combined with a variety of blur estimation methods.
Deep Multi-Scale Feature Learning for Defocus Blur Estimation
Sep 24, 2020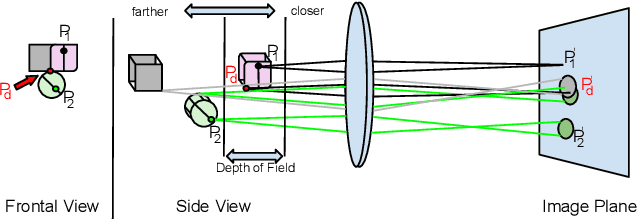
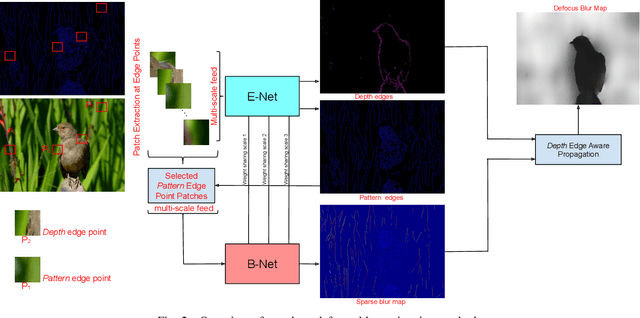

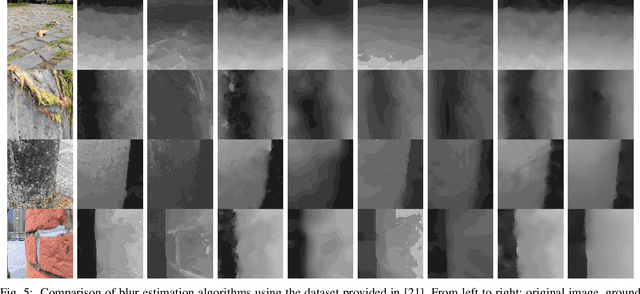
This paper presents an edge-based defocus blur estimation method from a single defocused image. We first distinguish edges that lie at depth discontinuities (called depth edges, for which the blur estimate is ambiguous) from edges that lie at approximately constant depth regions (called pattern edges, for which the blur estimate is well-defined). Then, we estimate the defocus blur amount at pattern edges only, and explore an interpolation scheme based on guided filters that prevents data propagation across the detected depth edges to obtain a dense blur map with well-defined object boundaries. Both tasks (edge classification and blur estimation) are performed by deep convolutional neural networks (CNNs) that share weights to learn meaningful local features from multi-scale patches centered at edge locations. Experiments on naturally defocused images show that the proposed method presents qualitative and quantitative results that outperform state-of-the-art (SOTA) methods, with a good compromise between running time and accuracy.
Collective behavior recognition using compact descriptors
Sep 27, 2018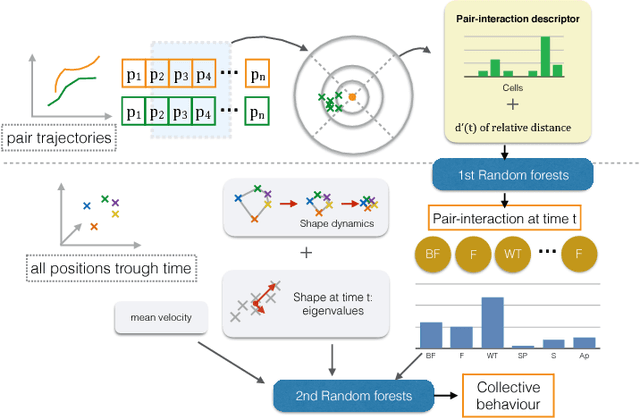
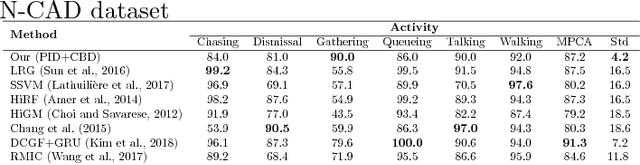
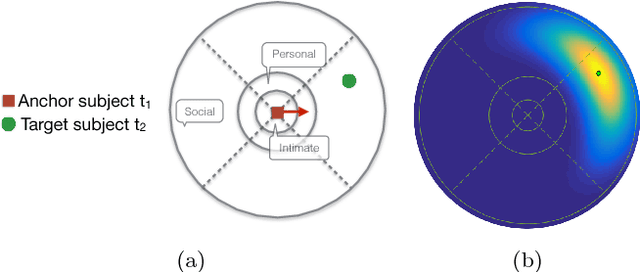
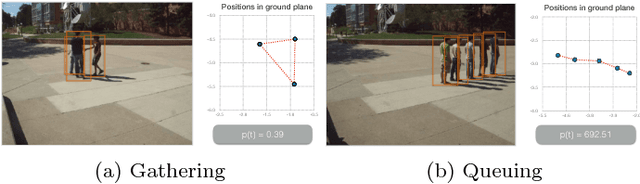
This paper presents a novel hierarchical approach for collective behavior recognition based solely on ground-plane trajectories. In the first layer of our classifier, we introduce a novel feature called Personal Interaction Descriptor (PID), which combines the spatial distribution of a pair of pedestrians within a temporal window with a pyramidal representation of the relative speed to detect pairwise interactions. These interactions are then combined with higher level features related to the mean speed and shape formed by the pedestrians in the scene, generating a Collective Behavior Descriptor (CBD) that is used to identify collective behaviors in a second stage. In both layers, Random Forests were used as classifiers, since they allow features of different natures to be combined seamlessly. Our experimental results indicate that the proposed method achieves results on par with state of the art techniques with a better balance of class errors. Moreover, we show that our method can generalize well across different camera setups through cross-dataset experiments.