 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Diversity in Discriminative Neural Networks
Jul 17, 2024Diversity is a concept of prime importance in almost all disciplines based on information processing. In telecommunications, for example, spatial, temporal, and frequency diversity, as well as redundant coding, are fundamental concepts that have enabled the design of extremely efficient systems. In machine learning, in particular with neural networks, diversity is not always a concept that is emphasized or at least clearly identified. This paper proposes a neural network architecture that builds upon various diversity principles, some of them already known, others more original. Our architecture obtains remarkable results, with a record self-supervised learning accuracy of 99. 57% in MNIST, and a top tier promising semi-supervised learning accuracy of 94.21% in CIFAR-10 using only 25 labels per class.
Sparse associative memory based on contextual code learning for disambiguating word senses
Nov 14, 2019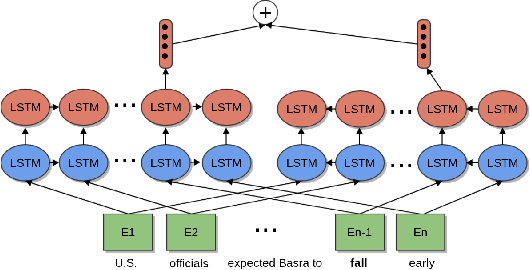
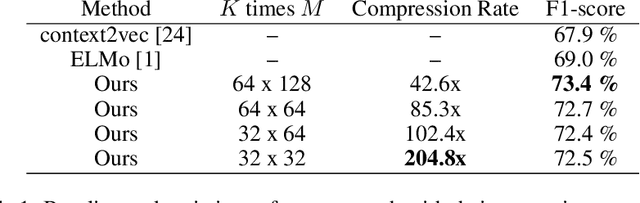
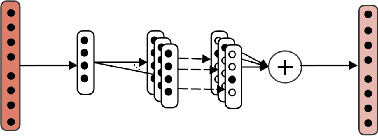

In recent literature, contextual pretrained Language Models (LMs) demonstrated their potential in generalizing the knowledge to several Natural Language Processing (NLP) tasks including supervised Word Sense Disambiguation (WSD), a challenging problem in the field of Natural Language Understanding (NLU). However, word representations from these models are still very dense, costly in terms of memory footprint, as well as minimally interpretable. In order to address such issues, we propose a new supervised biologically inspired technique for transferring large pre-trained language model representations into a compressed representation, for the case of WSD. Our produced representation contributes to increase the general interpretability of the framework and to decrease memory footprint, while enhancing performance.
Robust Associative Memories Naturally Occuring From Recurrent Hebbian Networks Under Noise
Sep 25, 2017
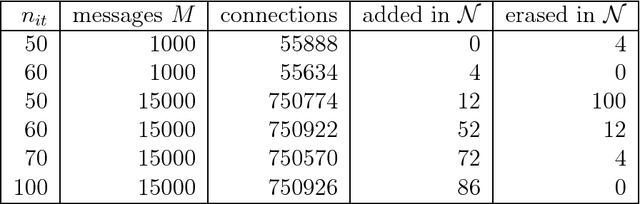
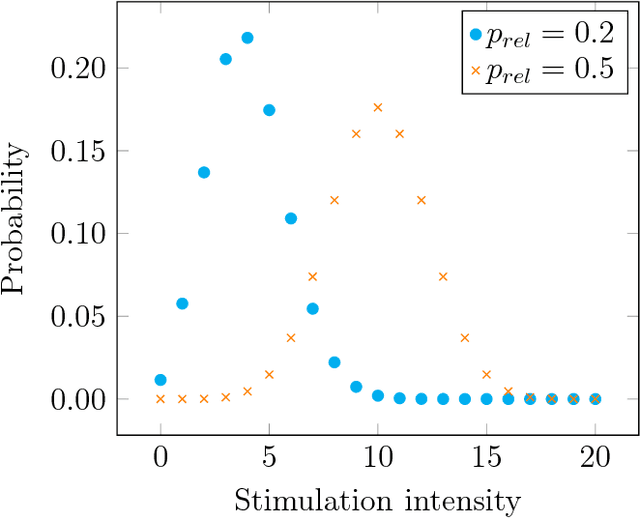
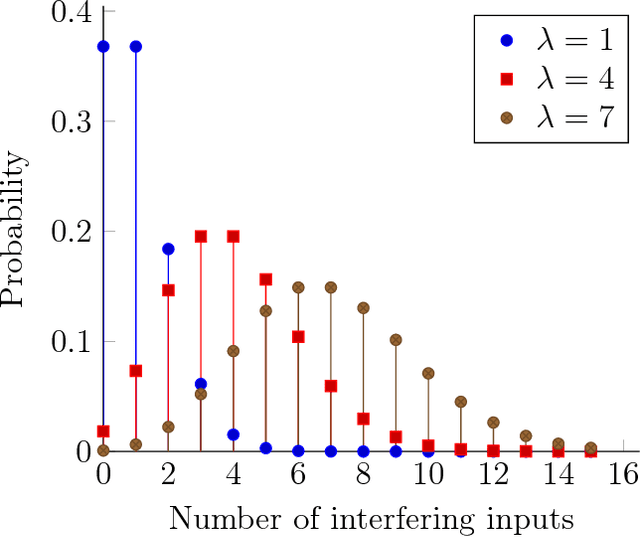
The brain is a noisy system subject to energy constraints. These facts are rarely taken into account when modelling artificial neural networks. In this paper, we are interested in demonstrating that those factors can actually lead to the appearance of robust associative memories. We first propose a simplified model of noise in the brain, taking into account synaptic noise and interference from neurons external to the network. When coarsely quantized, we show that this noise can be reduced to insertions and erasures. We take a neural network with recurrent modifiable connections, and subject it to noisy external inputs. We introduce an energy usage limitation principle in the network as well as consolidated Hebbian learning, resulting in an incremental processing of inputs. We show that the connections naturally formed correspond to state-of-the-art binary sparse associative memories.
Storing sequences in binary tournament-based neural networks
Sep 01, 2014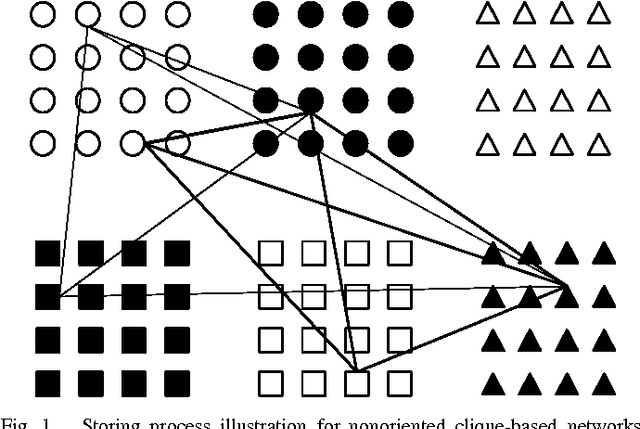
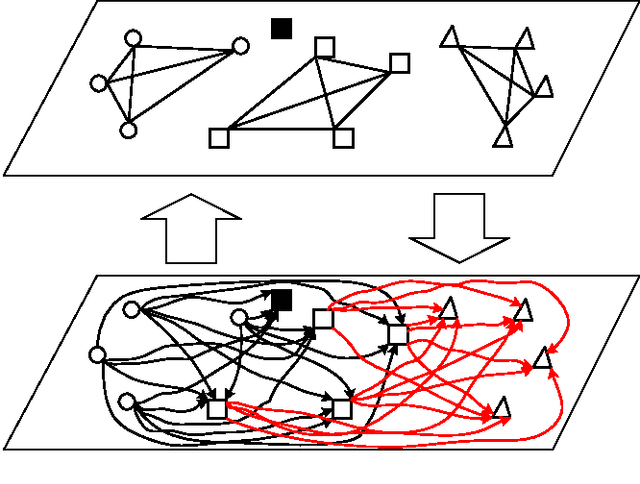
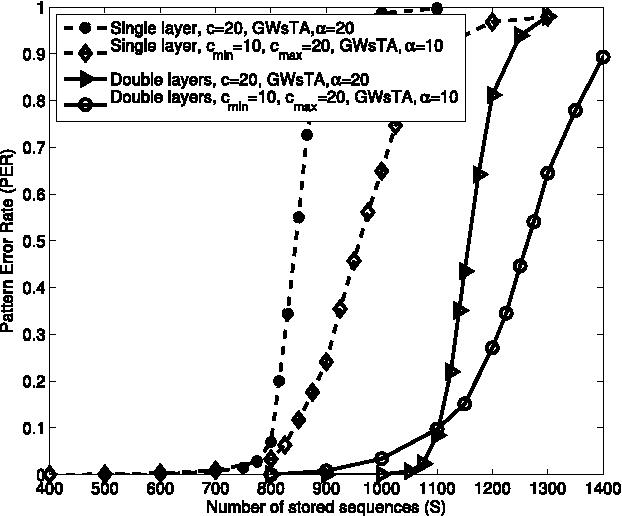
An extension to a recently introduced architecture of clique-based neural networks is presented. This extension makes it possible to store sequences with high efficiency. To obtain this property, network connections are provided with orientation and with flexible redundancy carried by both spatial and temporal redundancy, a mechanism of anticipation being introduced in the model. In addition to the sequence storage with high efficiency, this new scheme also offers biological plausibility. In order to achieve accurate sequence retrieval, a double layered structure combining hetero-association and auto-association is also proposed.
Learning sparse messages in networks of neural cliques
Aug 20, 2012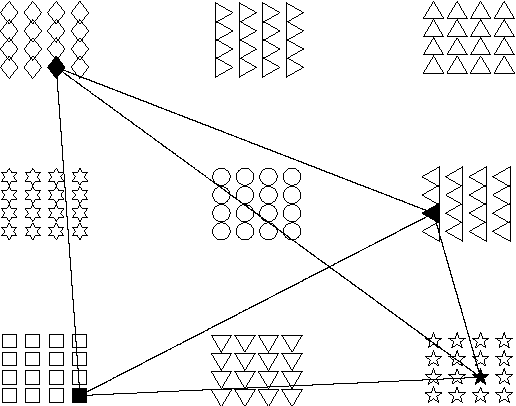
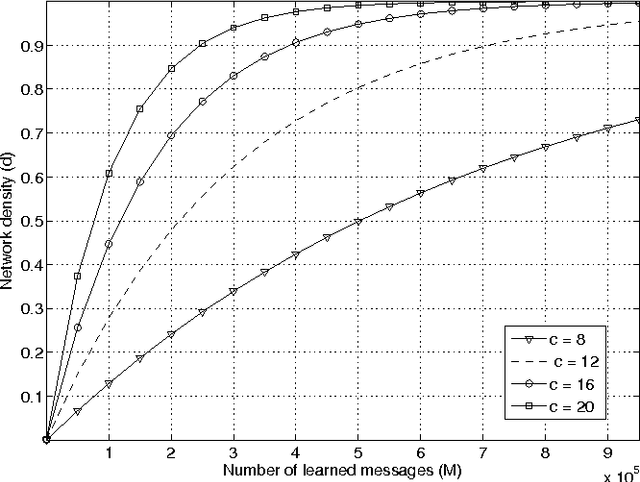
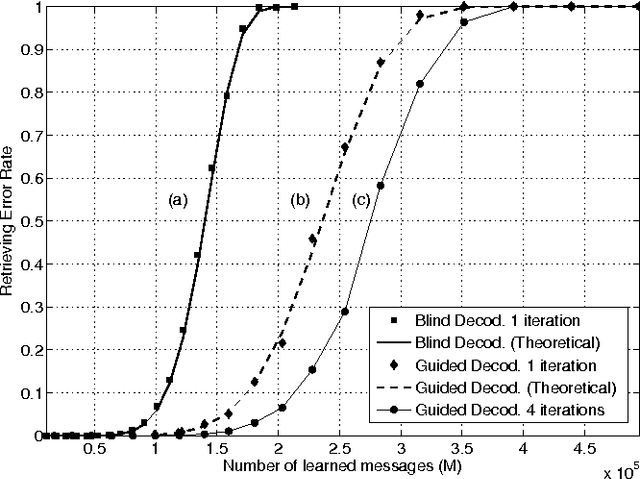
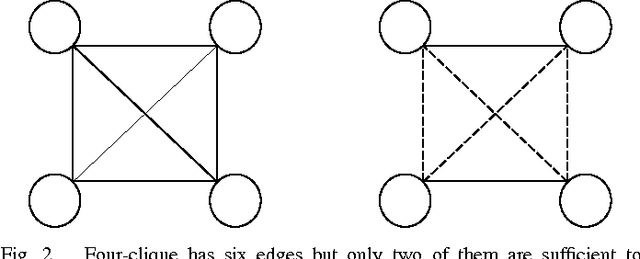
An extension to a recently introduced binary neural network is proposed in order to allow the learning of sparse messages, in large numbers and with high memory efficiency. This new network is justified both in biological and informational terms. The learning and retrieval rules are detailed and illustrated by various simulation results.
Sparse neural networks with large learning diversity
Feb 21, 2011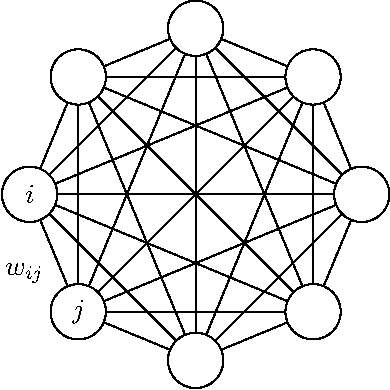
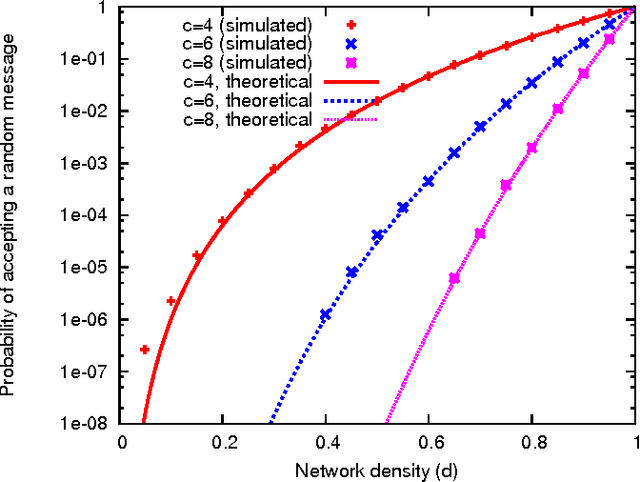
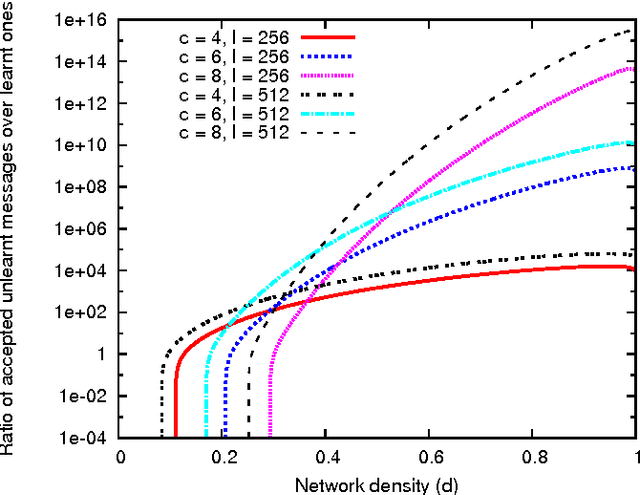
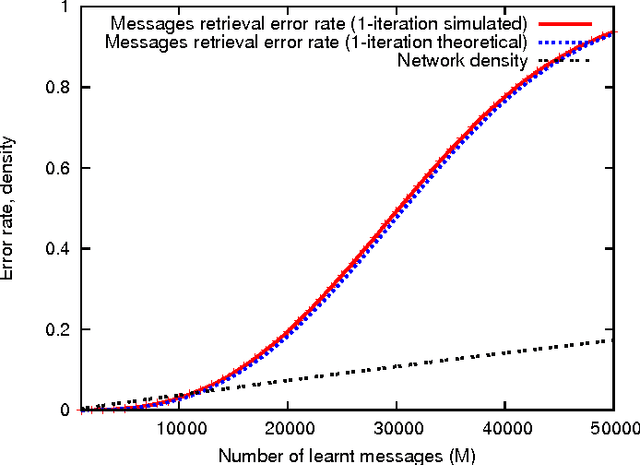
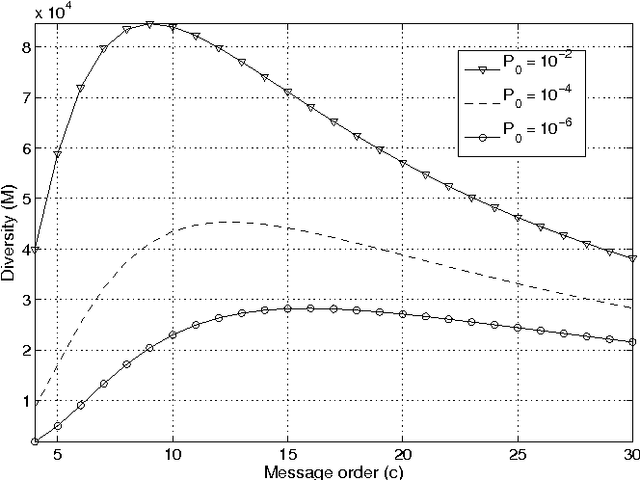
Coded recurrent neural networks with three levels of sparsity are introduced. The first level is related to the size of messages, much smaller than the number of available neurons. The second one is provided by a particular coding rule, acting as a local constraint in the neural activity. The third one is a characteristic of the low final connection density of the network after the learning phase. Though the proposed network is very simple since it is based on binary neurons and binary connections, it is able to learn a large number of messages and recall them, even in presence of strong erasures. The performance of the network is assessed as a classifier and as an associative memory.