 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigraphwave: Scalable Extraction of Structural Node Embeddings via Diffusion on Directed Graphs
Jul 20, 2022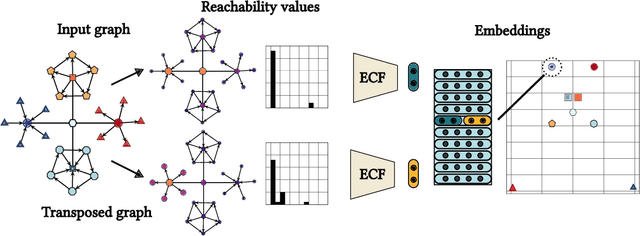

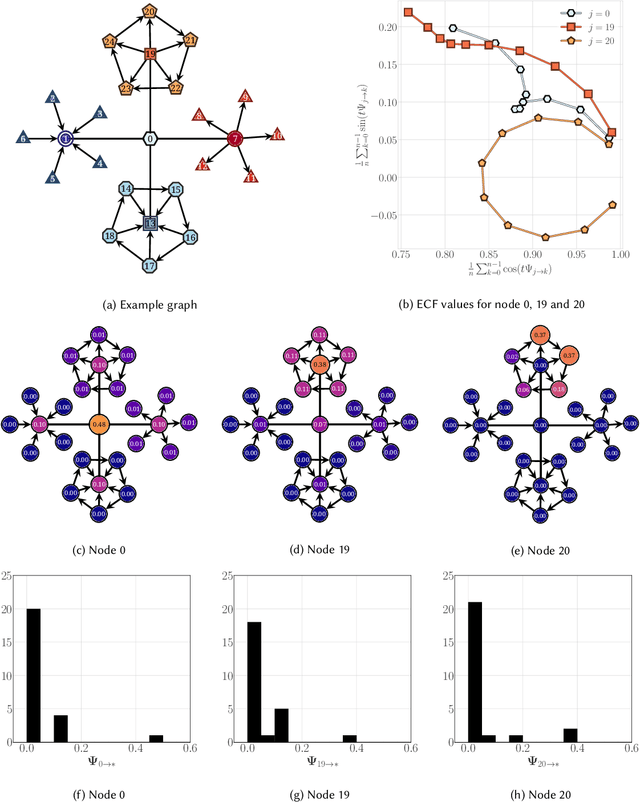
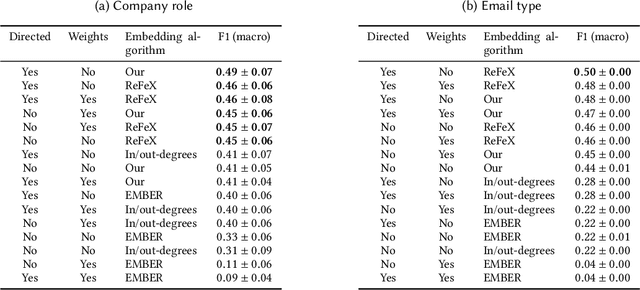
Structural node embeddings, vectors capturing local connectivity information for each node in a graph, have many applications in data mining and machine learning, e.g., network alignment and node classification, clustering and anomaly detection. For the analysis of directed graphs, e.g., transactions graphs, communication networks and social networks, the capability to capture directional information in the structural node embeddings is highly desirable, as is scalability of the embedding extraction method. Most existing methods are nevertheless only designed for undirected graph. Therefore, we present Digraphwave -- a scalable algorithm for extracting structural node embeddings on directed graphs. The Digraphwave embeddings consist of compressed diffusion pattern signatures, which are twice enhanced to increase their discriminate capacity. By proving a lower bound on the heat contained in the local vicinity of a diffusion initialization node, theoretically justified diffusion timescale values are established, and Digraphwave is left with only two easy-to-interpret hyperparameters: the embedding dimension and a neighbourhood resolution specifier. In our experiments, the two embedding enhancements, named transposition and aggregation, are shown to lead to a significant increase in macro F1 score for classifying automorphic identities, with Digraphwave outperforming all other structural embedding baselines. Moreover, Digraphwave either outperforms or matches the performance of all baselines on real graph datasets, displaying a particularly large performance gain in a network alignment task, while also being scalable to graphs with millions of nodes and edges, running up to 30x faster than a previous diffusion pattern based method and with a fraction of the memory consumption.
GraphDCA -- a Framework for Node Distribution Comparison in Real and Synthetic Graphs
Feb 09, 2022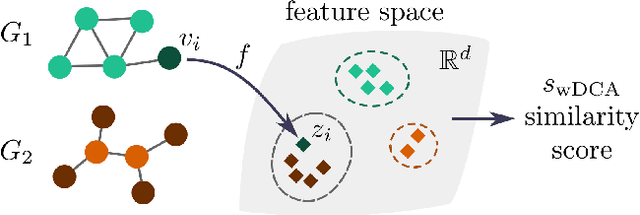


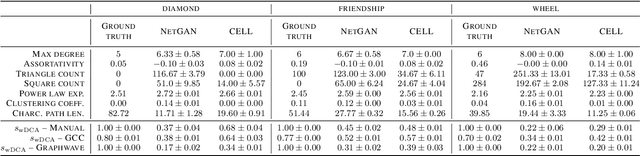
We argue that when comparing two graphs, the distribution of node structural features is more informative than global graph statistics which are often used in practice, especially to evaluate graph generative models. Thus, we present GraphDCA - a framework for evaluating similarity between graphs based on the alignment of their respective node representation sets. The sets are compared using a recently proposed method for comparing representation spaces, called Delaunay Component Analysis (DCA), which we extend to graph data. To evaluate our framework, we generate a benchmark dataset of graphs exhibiting different structural patterns and show, using three node structure feature extractors, that GraphDCA recognizes graphs with both similar and dissimilar local structure. We then apply our framework to evaluate three publicly available real-world graph datasets and demonstrate, using gradual edge perturbations, that GraphDCA satisfyingly captures gradually decreasing similarity, unlike global statistics. Finally, we use GraphDCA to evaluate two state-of-the-art graph generative models, NetGAN and CELL, and conclude that further improvements are needed for these models to adequately reproduce local structural features.
Conditional Noise-Contrastive Estimation of Unnormalised Models
Jun 10, 2018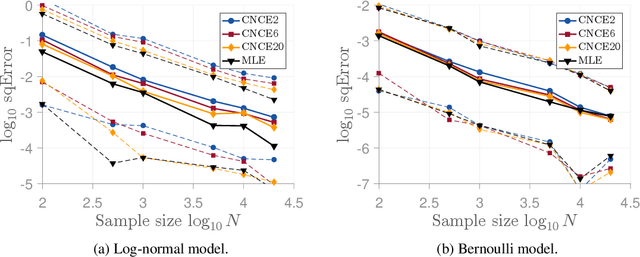


Many parametric statistical models are not properly normalised and only specified up to an intractable partition function, which renders parameter estimation difficult. Examples of unnormalised models are Gibbs distributions, Markov random fields, and neural network models in unsupervised deep learning. In previous work, the estimation principle called noise-contrastive estimation (NCE) was introduced where unnormalised models are estimated by learning to distinguish between data and auxiliary noise. An open question is how to best choose the auxiliary noise distribution. We here propose a new method that addresses this issue. The proposed method shares with NCE the idea of formulating density estimation as a supervised learning problem but in contrast to NCE, the proposed method leverages the observed data when generating noise samples. The noise can thus be generated in a semi-automated manner. We first present the underlying theory of the new method, show that score matching emerges as a limiting case, validate the method on continuous and discrete valued synthetic data, and show that we can expect an improved performance compared to NCE when the data lie in a lower-dimensional manifold. Then we demonstrate its applicability in unsupervised deep learning by estimating a four-layer neural image model.