 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Noise-Contrastive Estimation of Unnormalised Models
Paper and Code
Jun 10, 2018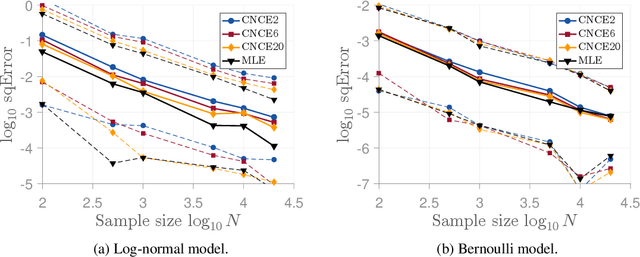


Many parametric statistical models are not properly normalised and only specified up to an intractable partition function, which renders parameter estimation difficult. Examples of unnormalised models are Gibbs distributions, Markov random fields, and neural network models in unsupervised deep learning. In previous work, the estimation principle called noise-contrastive estimation (NCE) was introduced where unnormalised models are estimated by learning to distinguish between data and auxiliary noise. An open question is how to best choose the auxiliary noise distribution. We here propose a new method that addresses this issue. The proposed method shares with NCE the idea of formulating density estimation as a supervised learning problem but in contrast to NCE, the proposed method leverages the observed data when generating noise samples. The noise can thus be generated in a semi-automated manner. We first present the underlying theory of the new method, show that score matching emerges as a limiting case, validate the method on continuous and discrete valued synthetic data, and show that we can expect an improved performance compared to NCE when the data lie in a lower-dimensional manifold. Then we demonstrate its applicability in unsupervised deep learning by estimating a four-layer neural image model.