 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM for Large-Scale Optimization Model Auto-Formulation: A Lightweight Few-Shot Learning Approach
Jan 14, 2026Large-scale optimization is a key backbone of modern business decision-making. However, building these models is often labor-intensive and time-consuming. We address this by proposing LEAN-LLM-OPT, a LightwEight AgeNtic workflow construction framework for LLM-assisted large-scale OPTimization auto-formulation. LEAN-LLM-OPT takes as input a problem description together with associated datasets and orchestrates a team of LLM agents to produce an optimization formulation. Specifically, upon receiving a query, two upstream LLM agents dynamically construct a workflow that specifies, step-by-step, how optimization models for similar problems can be formulated. A downstream LLM agent then follows this workflow to generate the final output. Leveraging LLMs' text-processing capabilities and common modeling practices, the workflow decomposes the modeling task into a sequence of structured sub-tasks and offloads mechanical data-handling operations to auxiliary tools. This design alleviates the downstream agent's burden related to planning and data handling, allowing it to focus on the most challenging components that cannot be readily standardized. Extensive simulations show that LEAN-LLM-OPT, instantiated with GPT-4.1 and the open source gpt-oss-20B, achieves strong performance on large-scale optimization modeling tasks and is competitive with state-of-the-art approaches. In addition, in a Singapore Airlines choice-based revenue management use case, LEAN-LLM-OPT demonstrates practical value by achieving leading performance across a range of scenarios. Along the way, we introduce Large-Scale-OR and Air-NRM, the first comprehensive benchmarks for large-scale optimization auto-formulation. The code and data of this work is available at https://github.com/CoraLiang01/lean-llm-opt.
NuwaTS: a Foundation Model Mending Every Incomplete Time Series
May 27, 2024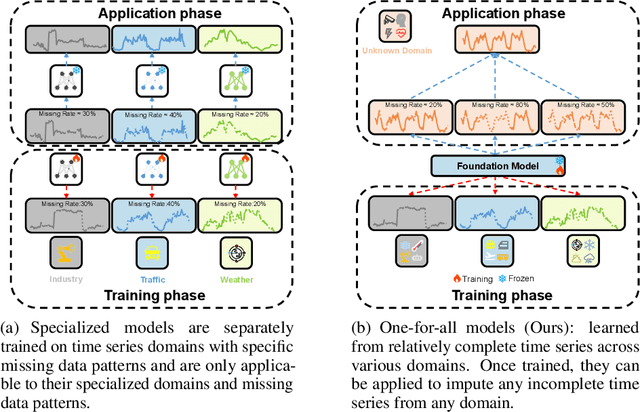

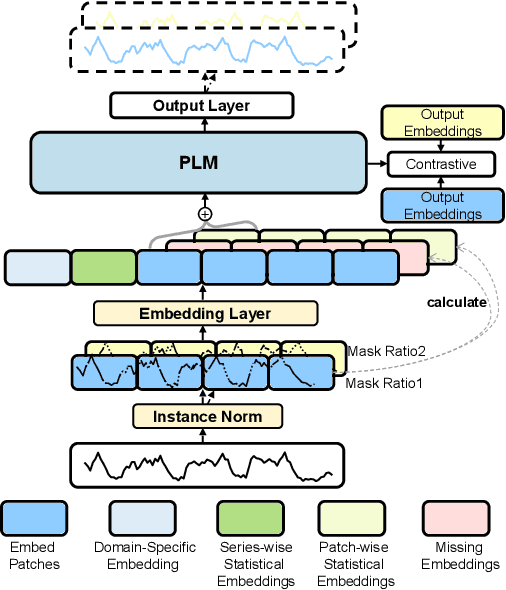
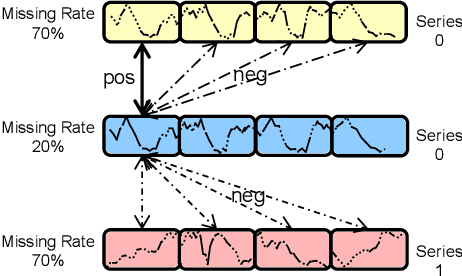
Time series imputation plays a crucial role in various real-world systems and has been extensively explored. Models for time series imputation often require specialization, necessitating distinct designs for different domains and missing patterns. In this study, we introduce NuwaTS, a framework to repurpose Pre-trained Language Model (PLM) for general time series imputation. Once trained, this model can be applied to imputation tasks on incomplete time series from any domain with any missing patterns. We begin by devising specific embeddings for each sub-series patch of the incomplete time series. These embeddings encapsulate information about the patch itself, the missing data patterns within the patch, and the patch's statistical characteristics. To enhance the model's adaptability to different missing patterns, we propose a contrastive learning approach to make representations of the same patch more similar across different missing patterns. By combining this contrastive loss with the missing data imputation task, we train PLMs to obtain a one-for-all imputation model. Furthermore, we utilize a plug-and-play layer-wise fine-tuning approach to train domain-specific models. Experimental results demonstrate that leveraging a dataset of over seventeen million time series from diverse domains, we obtain a one-for-all imputation model which outperforms existing domain-specific models across various datasets and missing patterns. Additionally, we find that NuwaTS can be generalized to other time series tasks such as forecasting. Our codes are available at https://github.com/Chengyui/NuwaTS.
Enhancing Representation Learning for Periodic Time Series with Floss: A Frequency Domain Regularization Approach
Aug 09, 2023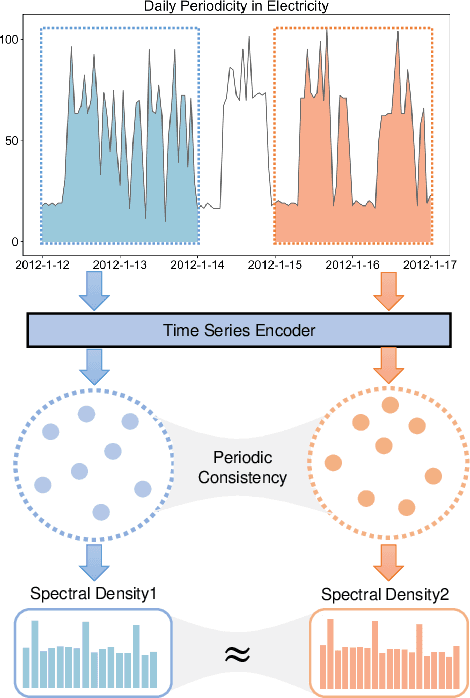

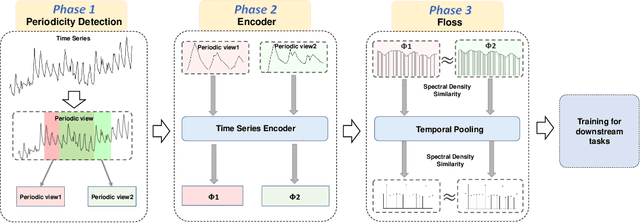

Time series analysis is a fundamental task in various application domains, and deep learning approaches have demonstrated remarkable performance in this area. However, many real-world time series data exhibit significant periodic or quasi-periodic dynamics that are often not adequately captured by existing deep learning-based solutions. This results in an incomplete representation of the underlying dynamic behaviors of interest. To address this gap, we propose an unsupervised method called Floss that automatically regularizes learned representations in the frequency domain. The Floss method first automatically detects major periodicities from the time series. It then employs periodic shift and spectral density similarity measures to learn meaningful representations with periodic consistency. In addition, Floss can be easily incorporated into both supervised, semi-supervised, and unsupervised learning frameworks. We conduct extensive experiments on common time series classification, forecasting, and anomaly detection tasks to demonstrate the effectiveness of Floss. We incorporate Floss into several representative deep learning solutions to justify our design choices and demonstrate that it is capable of automatically discovering periodic dynamics and improving state-of-the-art deep learning models.